Docker Avancé - Les orchestrateurs

Docker compose
Nous avons pu constater que lancer plusieurs conteneurs liés avec leur mapping réseau et les volumes liés implique des commandes assez lourdes. Cela devient ingérable si l'on a beaucoup d'applications microservice avec des réseaux et des volumes spécifiques.
Pour faciliter tout cela et dans l'optique d'Infrastructure as Code, Docker introduit un outil nommé docker-compose qui permet de décrire de applications multiconteneurs grâce à des fichiers YAML.
Pour bien comprendre qu'il s'agit au départ uniquement de convertir des options de commande Docker en YAML, un site vous permet de convertir une commande docker run en fichier Docker Compose : https://www.composerize.com/
Docker compose était un programme indépendant de Docker proposant un executable docker-compose à part. Depuis quelques temps cet outil a été intégré comme un plugin de la CLI Docker, le Compose Plugin.
On écrit maintenant les commandes compose comme une sous commande de docker: docker compose up
Le "langage" de Docker Compose
Documentation
- la documentation du langage (DSL) des compose-files
docker compose --helpN'hésitez pas à passer du temps à explorer les options et commandes dedocker-compose.
Syntaxe YAML
Alignement ! (2 espaces !!)
ALIGNEMENT !! (comme en python)
ALIGNEMENT !!! (le défaut du YAML, pas de correcteur syntaxique automatique, c'est bête mais vous y perdrez forcément quelques heures !
des listes (tirets)
des paires clé: valeur
Un peu comme du JSON, avec cette grosse différence que le JSON se fiche de l'alignement et met des accolades et des points-virgules
les extensions Docker et YAML dans VSCode vous aident à repérer des erreurs
Les erreurs courantes quotes, et deux-points :
titre: Un exemple: on va avoir des soucis
titre: "Un exemple: on va avoir des soucis"
Exemples de fichier Docker Compose
Une belle source d'exemples +- officielle: https://github.com/docker/awesome-compose
Sans build : un wordpress sur le port 80
version: '3.3'
services:
wordpress:
depends_on:
- mysqlpourwordpress
environment:
- "WORDPRESS_DB_HOST=mysqlpourwordpress:3306"
- WORDPRESS_DB_PASSWORD=monwordpress
- WORDPRESS_DB_USER=wordpress
networks:
- wordpress
ports:
- "80:80"
image: wordpress
volumes:
- wordpress_config:/var/www/html/
mysqlpourwordpress:
image: "mysql:5.7"
environment:
- MYSQL_ROOT_PASSWORD=motdepasseroot
- MYSQL_DATABASE=wordpress
- MYSQL_USER=wordpress
- MYSQL_PASSWORD=monwordpress
networks:
- wordpress
volumes:
- wordpress_data:/var/lib/mysql/
networks:
wordpress:
volumes:
wordpress_config:
wordpress_data:
Avec build : un ruby on rails sur le port 80
Un deuxième exemple :
version: '3.3'
services:
postgres:
image: postgres:10
environment:
POSTGRES_USER: rails_user
POSTGRES_PASSWORD: rails_password
POSTGRES_DB: rails_db
networks:
- back_end
redis:
image: redis:3.2-alpine
networks:
- back_end
rails:
build: .
depends_on:
- postgres
- redis
environment:
DATABASE_URL: "postgres://rails_user:rails_password@postgres:5432/rails_db"
REDIS_HOST: "redis:6379"
networks:
- front_end
- back_end
volumes:
- .:/app
nginx:
image: nginx:latest
networks:
- front_end
ports:
- 80:80
volumes:
- ./nginx.conf:/etc/nginx/conf.d/default.conf:ro
networks:
front_end:
back_end:
Utiliser Docker compose
Les commandes
Les commandes suivantes sont couramment utilisées lorsque vous travaillez avec Compose. La plupart se passent d'explications et ont des équivalents Docker directs, mais il vaut la peine d'en être conscient·e :
buildreconstruit toutes les images créées à partir de Dockerfiles. La commande up ne construira pas une image à moins qu'elle n'existe pas, donc utilisez cette commande à chaque fois que vous avez besoin de mettre à jour une image (quand vous avez édité un Dockerfile). On peut aussi fairedocker compose up --buildupdémarre tous les conteneurs définis dans le fichier compose et agrège la sortie des logs. Normalement, vous voudrez utiliser l'argument-dpour exécuter Compose en arrière-plan.runfait tourner un conteneur pour exécuter une commande unique. Cela aura aussi pour effet de faire tourner tout conteneur décrit dansdepends_on, à moins que l'argument--no-depsne soit donné.stoparrête les conteneurs sans les enlever.psfournit des informations sur le statut des conteneurs gérés par Compose.logsaffiche les logs. De façon générale la sortie des logs est colorée et agrégée pour les conteneurs gérés par Compose.downdétruit tous les conteneurs définis dans le fichier Compose, ainsi que les réseaux. Pour détruire les volumes et ainsi réinitialisé toutes les données on peut ajouter l'option-v.rmsupprime les conteneurs à l'arrêt. On peut aussi utiliser l'argument-vpour supprimer tous les volumes gérés par Docker.
Le workflow de développement Docker Compose
Compose est un outil d'infrastructure as code declaratif : à chaque fois qu'on lance docker compose up seul les conteneurs ayant changé dans le code sont mis à jour en fonction de la description dans le docker-compose.yml
workflow de base:
- lire/ecrire le code du
docker-compose.yml - facultatif:
docker compose buildsi besoin pour reconstruire les images docker ayant changé - facultatif: exécuter les taches de préparation avec
docker compose up <db>pour monter seulement certains conetenrus etdocker compose run <conteneur> <commande>pour préparer par exemple une base de donnée. voir section usage non synchrone plus bas. docker compose up -dva créer tous les conteneursdocker compose psetdocker compose logspour vérifier que tout se passe bien dans les conteneursdocker compose downtout arrêter quand on a fini de développer avec-ven plus si il faut nettoyer les données.
Usage non synchrone de docker-compose
On peut également exécuter des tâches une par une dans les conteneurs du docker-compose sans démarrer tous les conteneurs simultanéement. Comme par exemple pour une migration de base de donnée. Exemple : https://docs.funkwhale.audio/installation/docker.html#start-funkwhale-service
On peut également exécuter des tâches une par une dans les conteneurs du docker-compose sans démarrer tous les conteneurs simultanéement. Comme par exemple pour une migration de base de donnée.
Exemple : https://docs.funkwhale.audio/administrator/installation/docker.html#set-up-funkwhale
Visualisation des applications microservice complexes
Certaines applications microservice peuvent avoir potentiellement des dizaines de petits conteneurs spécialisés.
Le service devient alors difficile à lire dans le compose file.
Il est possible de visualiser l'architecture d'un fichier Docker Compose en utilisant docker-compose-viz:
- https://github.com/pmsipilot/docker-compose-viz
sudo apt-get install graphvizdocker run --rm -it --name dcv -v $(pwd):/input pmsipilot/docker-compose-viz render -m image docker-compose.yml
Cet outil peut être utilisé dans un cadre d'intégration continue pour produire automatiquement la documentation pour une image en fonction du code.
Docker Swarm
Docker swarm est la solution de Docker pour exécuter Docker sur plusieurs hôtes.
La solution n'a jamais résolu les problèmes complexes et d'échelle de la production.
Aujourd'hui le produit est toujours disponible mais n'a plus de visibilité pour l'avenir.
Introduction à Swarm
Se grouper par 2 ou 3 pour créer un cluster à partir de vos VM respectives (il faut utiliser une commande Swarm pour récupérer les instructions nécessaires :
docker swarm initdevrait vous orienter).Si grouper plusieurs des VM n'est pas possible, vous pouvez faire un cluster à un seul noeud, ou bien créer un cluster multi-nodes très simplement avec l'interface du site Play With Docker, il faut s'y connecter avec vos identifiants Docker Hub. Vous pouvez vous connecter à ces VM en SSH.
Vous pouvez faire
docker swarm --helppour obtenir des infos manquantes, ou fairedocker swarm leave --forcepour réinitialiser votre configuration Docker Swarm si besoin.N'hésitez pas à regarder dans les logs avec
systemctl status dockercomment se passe l'élection du nœud leader, à partir du moment où vous avez plus d'un manager.
Créer un service
Afin de visualiser votre installation Swarm, utilisons : https://github.com/dockersamples/docker-swarm-visualizer
docker run -d -p 8080:8080 -v /var/run/docker.sock:/var/run/docker.sock dockersamples/visualizer
En ligne de commande
En ligne de commande :
docker service create --name whoami --replicas 5 -p 9999:80 traefik/whoami
Avec la clé deploy:
A l'aide de la propriété deploy: de docker compose, créer un service en 5 exemplaires (replicas) à partir de l'image traefik/whoami accessible sur le port 9999 et connecté au port 80 des 5 replicas.
Correction
services:
whoami:
image: traefik/whoami
ports:
- 9999:80
deploy:
replicas: 5
Accédez à votre service depuis un node et actualisez plusieurs fois la page (Ctrl+Maj+R sinon le cache du navigateur vous embêtera). Les informations affichées changent. Pourquoi ?
- Lancez une commande
service scalepour changer le nombre de replicas de votre service et observez le changement avecdocker service ps hello
La stack example-voting-app
Cloner l'application
example-voting-appici : https://github.com/dockersamples/example-voting-appLire le schéma d'architecture de l'app
example-voting-appsur Github.Lire attentivement le fichier
docker-stack.yml. Ce sont des fichiers Docker Compose classiques avec différentes options liées à un déploiement via Swarm. Quelles options semblent spécifiques à Docker Swarm ? Ces options permettent de configurer des fonctionnalités d'orchestration.
Avec
docker swarm init, transformer son installation Docker en une installation Docker compatible avec Swarm. Lisez attentivement le message qui vous est renvoyé.Déployer la stack du fichier
docker-stack.yml:docker stack deploy --compose-file docker-stack.yml votedocker stack lsindique 6 services pour la stackvote. Observer également l'output dedocker stack ps voteet dedocker stack services vote. Qu'est-ce qu'un service dans la terminologie de Swarm ?Accéder aux différents front-ends de la stack grâce aux informations contenues dans les commandes précédentes. Sur le front-end lié au vote, actualiser plusieurs fois la page. Que signifie la ligne
Processed by container ID […]? Pourquoi varie-t-elle ?Scaler la stack en ajoutant des replicas du front-end lié au vote avec l'aide de
docker service --help. Accédez à ce front-end et vérifier que cela a bien fonctionné en actualisant plusieurs fois.
puis spécifier quelques options d'orchestration exclusives à Docker Swarm : que fait
mode: global? N'oubliez pas de redéployer votre Compose file.Avec Portainer ou avec docker-swarm-visualizer, explorer le cluster ainsi créé.
Opérer sur le cluster
Trouver la commande pour déchoir et promouvoir l'un de vos nœuds de
manageràworkeret vice-versa.Puis sortir un nœud du cluster (
drain) :docker node update --availability drain <node-name>
Installons Portainer
Portainer est une interface web de base pour gérer un cluster docker.
docker service create \
--name portainer \
--publish 9000:9000 \
--constraint 'node.role == manager' \
--mount type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock \
portainer/portainer \
-H unix:///var/run/docker.sock
- Listez les services
- Inspectez le service portainer avec l'option --pretty
- Ouvrez la page avec
firefox http://$(docker-machine ip <machine_manager>):9000-->
Facultatif : déployer une nouvelle image pour un service de example-voting-app
Tenter :
- de rebuild les différentes images à partir de leur Dockerfile,
- puis d'éditer votre fichier Docker Compose (
docker-stack.yml) pour qu'il se base sur l'image que vous venez de reconstruire. - et de déployer ces images, potentiellement en faisant varier les options de
update_config:. Un message de warning devrait apparaître, pourquoi ?
Facultatif : Gérer les données sensibles dans Swarm avec les secrets Docker
créer un secret avec :
echo "This is a secret" | docker secret create my_secret_datapermettre l'accès au secret via :
docker service create --name monservice --secret my_secret_data redis:alpinelire le contenu secret dans :
/var/run/my_secret_data
Facultatif : cluster Postgres haute dispo et Swarm
Objectif : Déployer un cluster postgres répliqué avec Swarm
Indice : https://www.crunchydata.com/blog/an-easy-recipe-for-creating-a-postgresql-cluster-with-docker-swarm
Kubernetes
Kubernetes est devenu la solution de facto pour résoudre les problématiques de déploiements d'images Docker à l'échelle.
La solution s'appuie sur une multitude de ressources qui composent des architectures articulables.
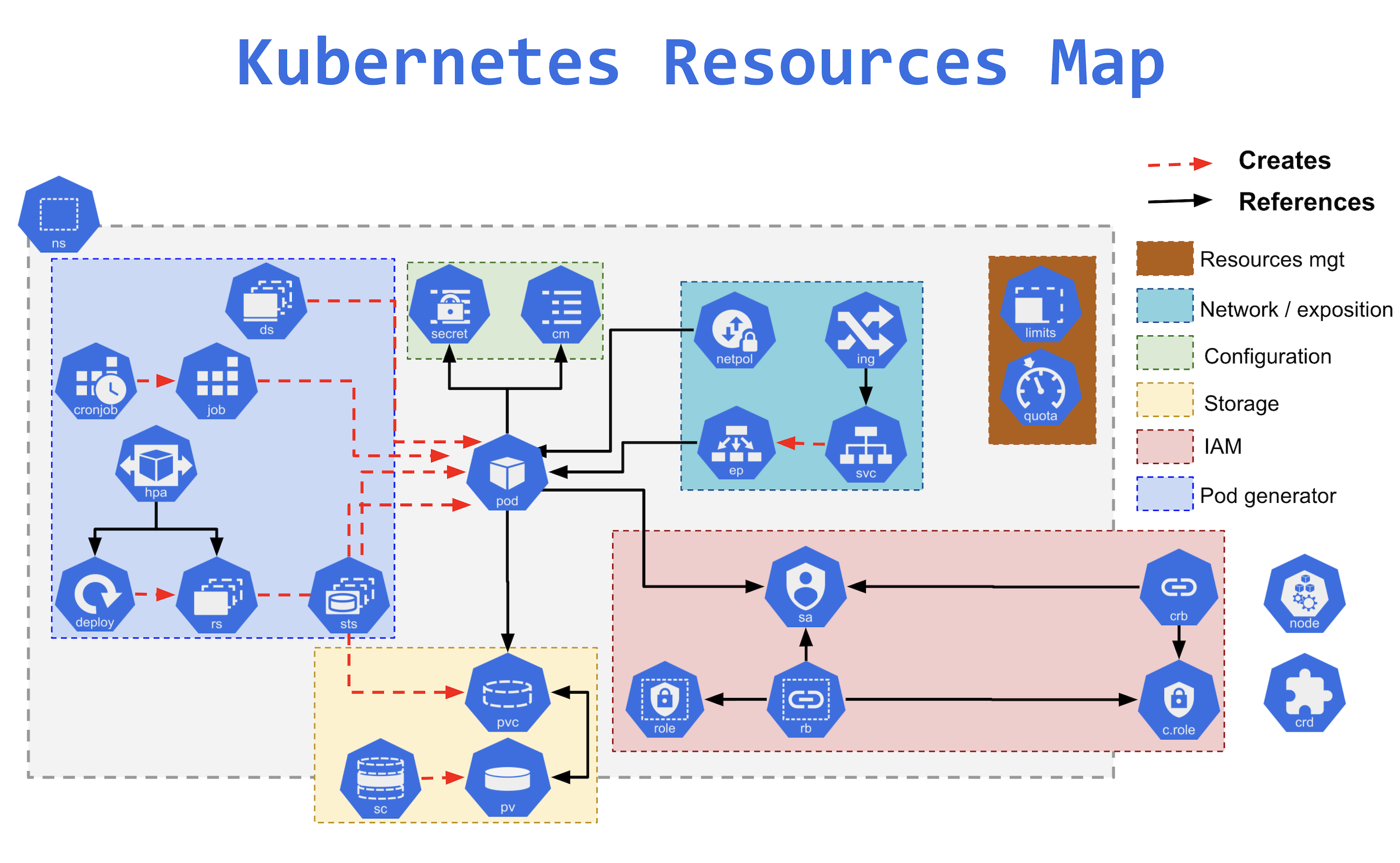
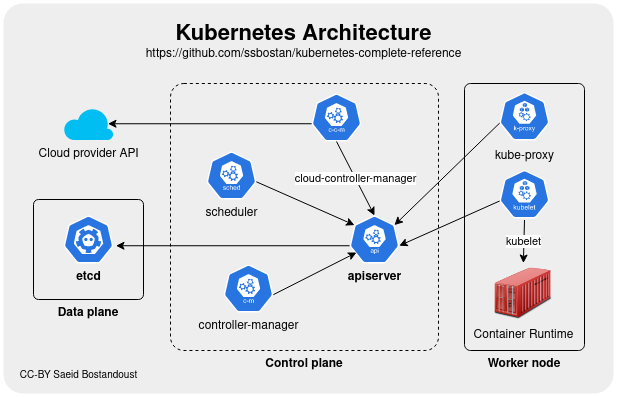
Désormais il existe de nombreuses solutions dérivées de cette architecture K8S.
MicroKube et k3s
Formules légères par rapport à k8s, qui visent à déployer sur un seul noeud.
K3S présente la capacité à opérer un cluster plus étendu si besoin.
AWS ECS / EKS, GKE, AKS
Amazon Elastic Container Service est une solution d'orchestration conçue et opérée en service managé par AWS. Code non libre.
Face au succès grandissant de Kubernetes, Amazon Kubernetes Service est apparu, pour fournir des clusters k8s par Amazon.
Google Cloud et Azure fournissent également des solutions qui visent à réduire la dépendance technique.
Ils fournissent également les services managés (Bases de données, stockage, réseau) permettant de gérer ses services externes dans un seul lieu.
Openshift
Solution commerciale de RedHat pour faire du Platform As A Service sur une base Kubernetes.
Disponible on premise ou sur de nombreux clouds, OpenShift intègre différents logiciels libres pour fournir out of the box des fonctionnalités avancées, y compris le build d'image automatisé.
- Ceph pour les volumes
- Prometheus pour le monitoring
- Istio pour le service mesh
Les fondamentaux de K8S
Tout est un conteneur
L'infrastructure logicielle de Kubernetes est basé un jeu d'API, implémenté par 2 outils interactifs en ligne de commande
- kubeadm pour les administrateurs
- kubectl pour les utilisateurs
De fait il existe des GUI permettant de piloter Kubernetes, comme Lens ou des panels web.
Les composants effectifs de Kubernetes (API, pilotage des noeuds, etc.) sont tous des conteneurs.
Ceci simplifie la mise à jour du système.
Un control plane d'administration et des nodes d'exécution
Le control plane est la partie administrative et les noeuds sont destinés aux conteneurs des utilisateurs.
Les noeuds reçoivent les demandes du control plane et les appliquent.
Le control plane est chargé de recevoir les appels d'API, de gérer les AAA (Authentification Authorisation Accounting), et de traiter l'orchestration.
Un système d'orchestration basé sur les intentions
Les manifestes envoyés par les utilisateurs définissent l'état idéal souhaité par l'utilisateur.
L'orchestrateur peut rejeter certaines requêtes invalides.
Les requêtes valides sont traitées de manière asynchrone selon un plan de réalisation ordonné.
De la sécurité intégrée et intégrable
K8S utilise du Role Based Access Control pour les utilisateurs, et des service accounts pour accéder à l'API.
Les ressources sont cloisonnées et limitées via des namespaces de cluster.
Les règles de sécurisation des conteneurs sont définies par les utilisateurs, mais on peut imposer des minimums (ex: no root user, read only, etc.).
Des règles de sécurité réseaux sont définies pour bloquer les flux indésirables.
Et il existe tout un écosystème de solutions dédiées, comme Falco qui surveille au niveau des appels système que rien d'anormal ne se produise, et logge tous les appels.
Introduction à Kubernetes
Le fichier kube-deployment.yml de l'app example-voting-app décrit la même app pour un déploiement dans Kubernetes plutôt que dans Docker Compose ou Docker Swarm.
Tentez de retrouver quelques équivalences entre Docker Compose / Swarm et Kubernetes en lisant attentivement ce fichier qui décrit un déploiement Kubernetes.
Installation de K3S
K3S installe son propre client kubectl.
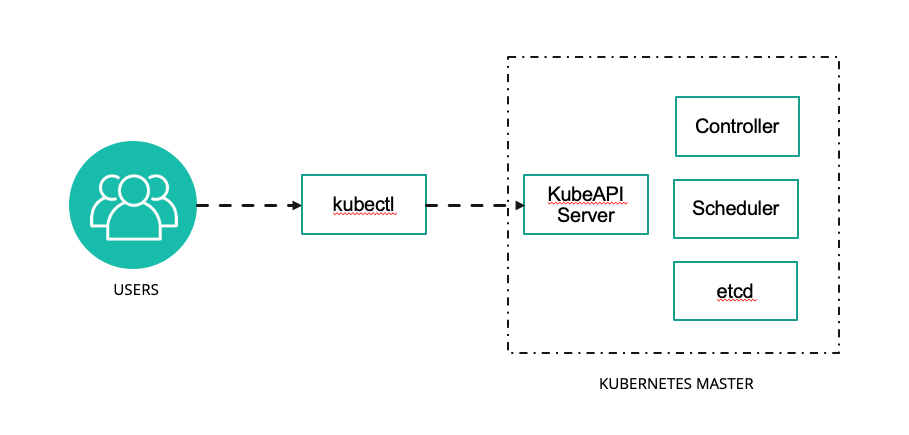
Pour s'assurer que c'est le bon kubectl qu'on utilise, sur Ubuntu on fait : sudo snap remove kubectl.
L'installation de K3S est volontairement simplissime comme vous pouvez le voir sur https://docs.k3s.io/quick-start
curl -sfL https://get.k3s.io | sh -
- Faites
kubectl versionpour afficher la version du client kubectl.
Bash completion et racourcis
Pour permettre à kubectl de compléter le nom des commandes et ressources avec <Tab> il est utile d'installer l'autocomplétion pour Bash :
sudo apt install bash-completion
source <(kubectl completion bash)
echo "source <(kubectl completion bash)" >> ${HOME}/.bashrc
Vous pouvez désormais appuyer sur <Tab> pour compléter vos commandes kubectl, c'est très utile !
- Notez également que pour gagner du temps en ligne de commande, la plupart des mots-clés de type Kubernetes peuvent être abrégés :
servicesdevientsvcdeploymentsdevientdeploy- etc.
La liste complète : https://blog.heptio.com/kubectl-resource-short-names-heptioprotip-c8eff9fb7202
Explorons notre cluster k8s
Notre cluster k8s est plein d'objets divers, organisés entre eux de façon dynamique pour décrire des applications, tâches de calcul, services et droits d'accès. La première étape consiste à explorer un peu le cluster :
- Listez les nodes pour récupérer le nom de l'unique node (
kubectl get nodes) puis affichez ses caractéristiques aveckubectl describe node.
La commande get est générique et peut être utilisée pour récupérer la liste de tous les types de ressources ou d'afficher les informations d'un resource précise.
Pour désigner un seul objet, il faut préfixer le nom de l'objet par son type (ex : kubectl get nodes XXX ou kubectl get node/XXX) car k8s ne peut pas deviner ce que l'on cherche quand plusieurs ressources de types différents ont le même nom.
De même, la commande describe peut s'appliquer à tout objet k8s.
Pour afficher tous les types de ressources à la fois que l'on utilise : kubectl get all
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2m34s
Il semble qu'il n'y a qu'une ressource dans notre cluster. Il s'agit du service d'API Kubernetes, pour que les pods/conteneurs puissent utiliser la découverte de service pour communiquer avec le cluster.
En réalité il y en a généralement d'autres cachés dans les autres namespaces. En effet les éléments internes de Kubernetes tournent eux-mêmes sous forme de services et de daemons Kubernetes. Les namespaces sont des groupes qui servent à isoler les ressources de façon logique et en termes de droits (avec le Role-Based Access Control (RBAC) de Kubernetes).
Pour vérifier cela on peut :
- Afficher les namespaces :
kubectl get namespaces
Un cluster Kubernetes a généralement un namespace appelé default dans lequel les commandes sont lancées et les ressources créées si on ne précise rien. Il a également aussi un namespace kube-system dans lequel résident les processus et ressources système de k8s. Pour préciser le namespace on peut rajouter l'argument -n à la plupart des commandes k8s.
Pour lister les ressources liées au cluster:
kubectl get all -n kube-system.Ou encore :
kubectl get all --all-namespaces(peut être abrégé enkubectl get all -A) qui permet d'afficher le contenu de tous les namespaces en même temps.Pour avoir des informations sur un namespace :
kubectl describe namespace/kube-system
Déployer une application en CLI
Nous allons maintenant déployer une première application conteneurisée. Le déploiement est un peu plus complexe qu'avec Docker, en particulier car il est séparé en plusieurs objets et plus configurable.
- Pour créer un déploiement en ligne de commande (par opposition au mode déclaratif que nous verrons plus loin), on peut lancer par exemple:
kubectl create deployment demonstration --image=monachus/rancher-demo
Cette commande crée un objet de type deployment. Nous pouvons étudier ce deployment avec la commande kubectl describe deployment/demonstration.
- Notez la liste des événements sur ce déploiement en bas de la description.
- De la même façon que dans la partie précédente, listez les
podsaveckubectl. Combien y en a-t-il ?
Agrandissons ce déploiement avec kubectl scale deployment demonstration --replicas=5
kubectl describe deployment/demonstrationpermet de constater que le service est bien passé à 5 replicas.- Observez à nouveau la liste des évènements, le scaling y est enregistré...
- Listez les pods pour constater
A ce stade impossible d'afficher l'application : le déploiement n'est pas encore accessible de l'extérieur du cluster.
Pour régler cela nous devons l'exposer grace à un service :
kubectl expose deployment demonstration --type=NodePort --port=8080 --name=demonstration-serviceAffichons la liste des services pour voir le résultat:
kubectl get services
Un service permet de créer un point d'accès unique exposant notre déploiement.
Ici nous utilisons le type Nodeport car nous voulons que le service soit accessible de l'extérieur par l'intermédiaire d'un forwarding de port.
Une méthode pour accéder à un service (quel que soit sont type) en mode développement est de forwarder le traffic par l'intermédiaire de kubectl (et des composants kube-proxy installés sur chaque noeuds du cluster).
- Pour cela on peut par exemple lancer:
kubectl port-forward svc/demonstration-service 8080:8080 --address 127.0.0.1 - Vous pouvez désormais accéder à votre app via via kubectl sur:
http://localhost:8080. Quelle différence avec l'exposition précédente via minikube ?
=> Un seul conteneur s'affiche. En effet kubectl port-forward sert à créer une connexion de developpement/debug qui pointe toujours vers le même pod en arrière plan.
Pour exposer cette application en production sur un véritable cluster, nous devrions plutôt avoir recours à service de type un LoadBalancer. Mais minikube ne propose pas par défaut de loadbalancer. Nous y reviendrons dans le cours sur les objets kubernetes.
Désinstaller k3s
Pour éviter des effets de bord, lancer le script de désinstallation :
/usr/local/bin/k3s-uninstall.sh
CheatSheet pour kubectl et formattage de la sortie
https://kubernetes.io/docs/reference/kubectl/cheatsheet/
Vous noterez dans cette page qu'il est possible de traiter la sortie des commandes kubectl de multiple façon (yaml, json, gotemplate, jsonpath, etc)
Le mode de sortie le plus utilisé pour filtrer une information parmis l'ensemble des caractéristiques d'une resource est jsonpath qui s'utilise comme ceci:
kubectl get pod <tab>
kubectl get pod demonstration-7645747fc6-f5z55 -o yaml # pour afficher la spécification
kubectl get pod demonstration-7645747fc6-f5z55 -o jsonpath='{.spec.containers[0].image}' # affiche le nom de l'image
Essayez de la même façon d'afficher le nombre de répliques de notre déploiement.
Des outils CLI supplémentaires
kubectl est puissant et flexible mais il est peu confortable certaines actions courantes. Il est intéressant d'ajouter d'autres outils pour le complémenter :
pour visualiser en temps réel les resources du cluster et leur évolution on installera
watchou plus confortableviddypour ajouter des plugins à kubectl on peut utiliser
krew: https://krew.sigs.k8s.io/docs/user-guide/setup/install/pour changer de cluster et de namespace efficacement on peut utiliser
kubectxetkubens:kubectl krew install ctx,kubectl krew install nspour visualiser les logs d'un déploiement/service on peut utiliser
stern:kubectl krew install stern