2-05 Bonnes pratiques d'organisation des fichiers et dossiers d'un projet
Objectifs
- Comprendre comment bien structurer ses projets dans Terraform avec Terragrunt
Architecture modulaire
Point sur les parties statiques et dynamiques de l'infrastructure
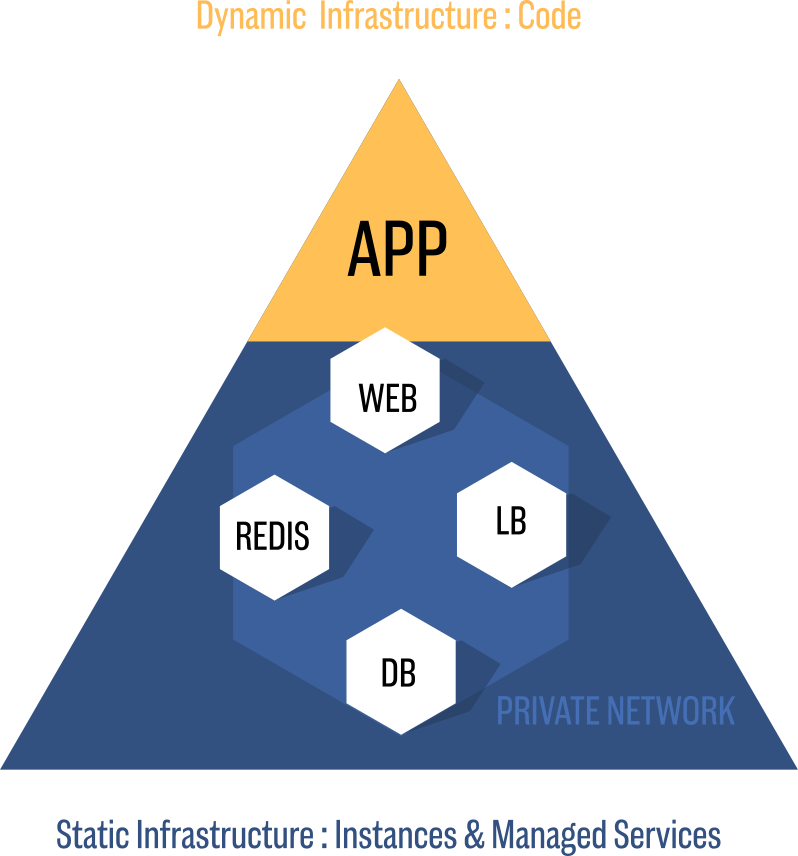
Certaines parties de l'infrastructure vont évoluer plus rapidement et nécessiter des mises à jour plus fréquentes que d'autres.
Pour prendre le cas le plus sensible, une base de données de production n'est pas censé bouger, hormis quand on orchestre une migration pour changer de version.
Ces parties de l'infrastructure peuvent considérées comme "statiques".
À l'inverse, le code d'une application peut évoluer plusieurs fois par jour, et dans une infrastructure élastique les noeuds de calculs sont par nature transients.
On va appeler "dynamiques" ces parties de l'infrastructure.
Il y a a plusieurs avantages à séparer dans l'IAC les parties statiques et dynamiques.
- Assurance : éviter le risque de détruire par erreur une base de données
- Rapidité : éviter de perdre du temps dans de la planification et du déploiement
- Sobriété : éviter les surconsommations d'énergie / réseau / disque
Conséquence 1 : séparer le code des différentes parties
On va segmenter le projet en modules différents.
Dans notre exemple, le déploiement de la base de données et la gestion des serveurs web sont dans deux modules séparés.
Conséquence 2 : utiliser des méthodes de déploiement légères pour les parties dynamiques
On va utiliser des outils adaptés à de la CI/CD pour les déploiements réguliers.
La bonne solution dépend des compétences techniques de l'équipe.
Aujourd'hui on conseillerait d'utiliser Kubernetes et des images de conteneurs comme méthode de déploiement du code.
Mais K8s n'est pas simple, et dans des cas plus raisonnables on peut utiliser ansible en coordination avec des utilitaires de déploiement continu.
Ansible va utiliser un inventaire dynamique, basé sur les API du cloud provider voire même en utilisant l'état Terraform.
Les utilitaires de déploiement vont récupérer à la demande les nouvelles versions du code, qui peut être déployé via
- des conteneurs : docker-compose
- des
git pull: capistrano et ses alternatives
Point sur l'architecture modulaire, les workspaces et les fichiers d'états
Notre vision de Terraform a évolué : il y a des limitations d'usage dans ces techniques un peu complexes, et on voit qu'il faut bien structurer son code à terme.
Nous allons voir que sur cette base le logiciel terragrunt va nous permettre de résoudre plusieurs problèmes avec quelques principes de base.
- Don't Repeat Yourself (DRY) : éviter la répétition du code
- Usage de conventions structurelles : travailler uniquement avec des modules
- Standardisation des environnements : gestions des états d'infrastructure
Terragrunt
La ligne de commande terragrunt
À la base, Terragrunt est une "surcouche" qui va piloter terraform pour vous.
Les versions de Terragrunt sont à aligner avec celles de Terraform.
Pour lancer Terragrunt, on utilisera les mêmes actions que Terraform
$ terragrunt init
$ terragrunt plan
$ terragrunt apply
$ terragrunt destroy
Mais là où Terragrunt va présenter une différence, c'est qu'il peut opérer sur plusieurs recettes à la fois.
$ terragrunt run-all apply
$ terragrunt run-all destroy
Terragrunt : Terraform sous stéroïdes
Avec Terragrunt, on passe d'une structure redondante :
└── live
├── prod
│ ├── app
│ │ └── main.tf + variables.tf + output.tf + ...
│ ├── mysql
│ │ └── main.tf + variables.tf + output.tf + ...
│ └── vpc
│ └── main.tf + variables.tf + output.tf + ...
├── qa
│ ├── app
│ │ └── main.tf + variables.tf + output.tf + ...
│ ├── mysql
│ │ └── main.tf + variables.tf + output.tf + ...
│ └── vpc
│ └── main.tf + variables.tf + output.tf + ...
└── stage
├── app
│ └── main.tf + variables.tf + output.tf + ...
├── mysql
│ └── main.tf + variables.tf + output.tf + ...
└── vpc
└── main.tf + variables.tf + output.tf + ...
à ça
└── live
├─ terragrunt.hcl
├── prod
│ ├── app
│ │ └── terragrunt.hcl (v 1.7.4)
│ ├── mysql
│ │ └── terragrunt.hcl (v 2.1.0)
│ └── vpc
│ └── terragrunt.hcl (v 1.8.2)
├── qa
│ ├── app
│ │ └── terragrunt.hcl (v 1.7.5)
│ ├── mysql
│ │ └── terragrunt.hcl (v 2.1.0)
│ └── vpc
│ └── terragrunt.hcl (v 1.8.3)
└── stage
├── app
│ └── terragrunt.hcl (v 1.7.7)
├── mysql
│ └── terragrunt.hcl (v 2.1.2)
└── vpc
└── terragrunt.hcl (v 1.8.3)
Gestion des dépendances
Chaque fichier terragrunt.hcl contient les informations nécessaires pour gérer l'infrastructure via Terraform.
terraform {
# Deploy version v0.0.3 in stage
source = "git::git@github.com:foo/modules.git//app?ref=v0.0.3"
}
inputs = {
instance_count = 3
instance_type = "t2.micro"
}
Gestion des backends de fichiers d'état
On a vu une limitation des backends : impossible d'utiliser des variables quand on déclare un backend de remote state.
Et il fallait créer le bucket S3 pour stocker notre remote state séparément.
Avec Terragrunt, on a une syntaxe qui va prendre ça en charge.
remote_state {
backend = "s3"
generate = {
path = "backend.tf"
if_exists = "overwrite"
}
config = {
bucket = "my-terraform-state"
key = "${path_relative_to_include()}/terraform.tfstate"
region = "us-east-1"
encrypt = true
dynamodb_table = "my-lock-table"
}
}
Et d'autres avantages...
Parmi les aspects pratiques de Terraform, on peut utiliser des "hooks" qui déclenchent des actions à des moments clefs.
terraform {
# Pull the terraform configuration at the github repo "acme/infrastructure-modules", under the subdirectory
# "networking/vpc", using the git tag "v0.0.1".
source = "git::git@github.com:acme/infrastructure-modules.git//networking/vpc?ref=v0.0.1"
# For any terraform commands that use locking, make sure to configure a lock timeout of 20 minutes.
extra_arguments "retry_lock" {
commands = get_terraform_commands_that_need_locking()
arguments = ["-lock-timeout=20m"]
}
# You can also specify multiple extra arguments for each use case. Here we configure terragrunt to always pass in the
# `common.tfvars` var file located by the parent terragrunt config.
extra_arguments "custom_vars" {
commands = [
"apply",
"plan",
"import",
"push",
"refresh"
]
required_var_files = ["${get_parent_terragrunt_dir()}/common.tfvars"]
}
# The following are examples of how to specify hooks
# Before apply or plan, run "echo Foo".
before_hook "before_hook_1" {
commands = ["apply", "plan"]
execute = ["echo", "Foo"]
}
# Before apply, run "echo Bar". Note that blocks are ordered, so this hook will run after the previous hook to
# "echo Foo". In this case, always "echo Bar" even if the previous hook failed.
before_hook "before_hook_2" {
commands = ["apply"]
execute = ["echo", "Bar"]
run_on_error = true
}
# After running apply or plan, run "echo Baz". This hook is configured so that it will always run, even if the apply
# or plan failed.
after_hook "after_hook_1" {
commands = ["apply", "plan"]
execute = ["echo", "Baz"]
}
# After an error occurs during apply or plan, run "echo Error Hook executed". This hook is configured so that it will run
# after any error, with the ".*" expression.
error_hook "error_hook_1" {
commands = ["apply", "plan"]
execute = ["echo", "Error Hook executed"]
on_errors = [
".*",
]
}
}
Gestion de l'architecture DRY
Pour éviter de se répéter entre configurations d'environnement, Terragrunt utilise une directive include.
└── live
├── terragrunt.hcl
├── _env
│ ├── app.hcl
│ ├── mysql.hcl
│ └── vpc.hcl
├── prod
│ ├── app
│ │ └── terragrunt.hcl
│ ├── mysql
│ │ └── terragrunt.hcl
│ └── vpc
│ └── terragrunt.hcl
## File: _env:app.hcl
terraform {
source = "github.com/<org>/modules.git//app?ref=v0.1.0"
}
dependency "vpc" {
config_path = "../vpc"
}
dependency "mysql" {
config_path = "../mysql"
}
inputs = {
basename = "example-app"
vpc_id = dependency.vpc.outputs.vpc_id
subnet_ids = dependency.vpc.outputs.subnet_ids
mysql_endpoint = dependency.mysql.outputs.endpoint
}
## File: prod/app/terragrunt.hcl
include "root" {
path = find_in_parent_folders()
}
include "env" {
path = "${get_terragrunt_dir()}/../../_env/app.hcl"
}
inputs = {
env = "prod"
}
Rappel des objectifs
- Comprendre comment bien structurer ses projets dans Terraform avec Terragrunt