Kubernetes pour développeurs
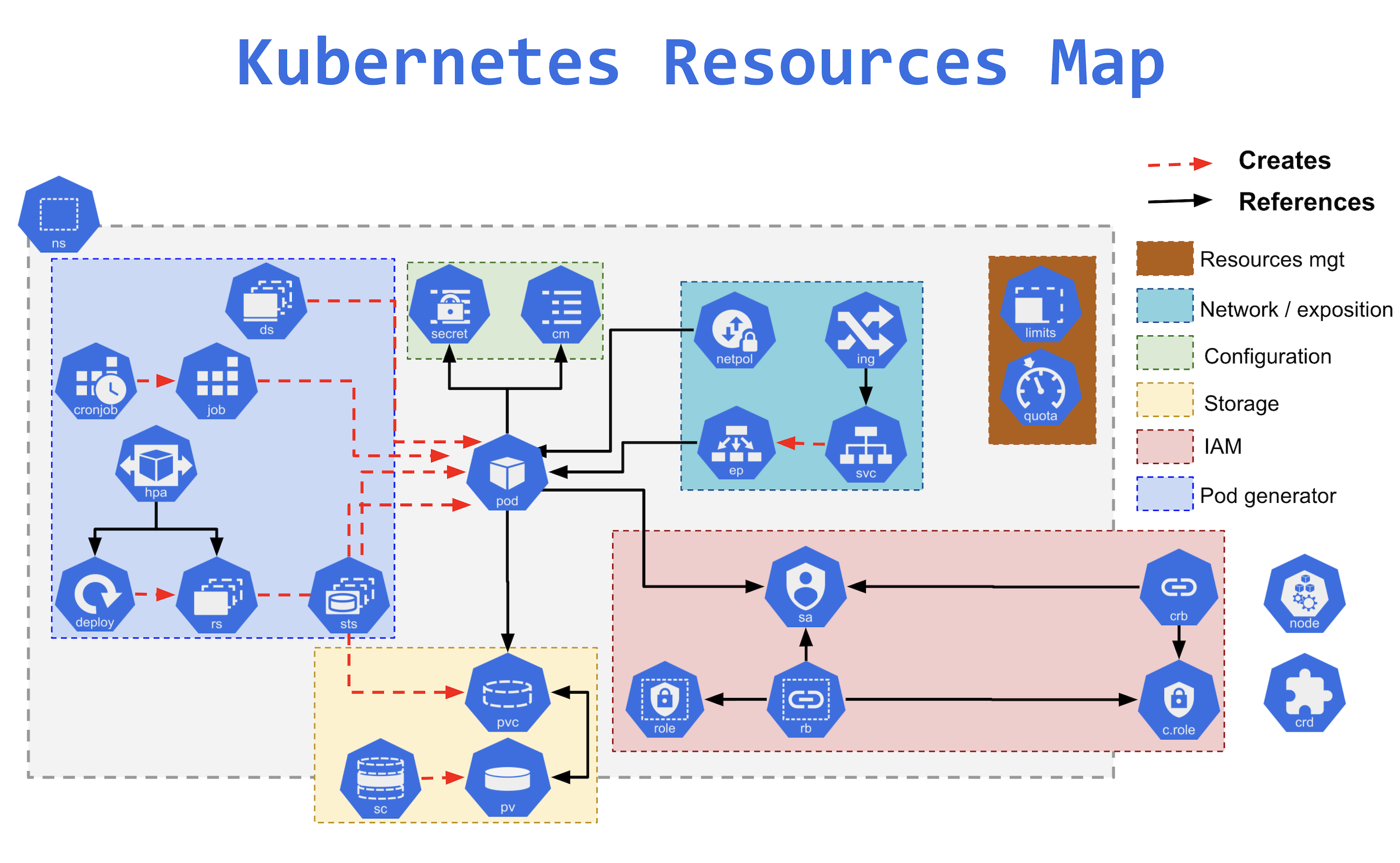
Les objets de configuration : ConfigMaps et Secrets
D'après les recommandations 12factor, la configuration de nos programmes doit venir de l'environnement — séparée du code.
ConfigMaps
Les objets ConfigMaps permettent d'injecter dans des pods des ensembles clé/valeur de configuration, soit comme variables d'environnement, soit comme fichiers montés en volume.
Cela permet de centraliser et découpler la configuration du déploiement des pods. Plusieurs microservices peuvent partager la même ConfigMap pour une valeur commune (ex : nom de domaine d'une base de données).
Exemple : ConfigMap et variable d'environnement
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql-config
data:
MYSQL_DATABASE: mydatabase
apiVersion: apps/v1
kind: Deployment
metadata:
name: mysql-deployment
spec:
replicas: 1
selector:
matchLabels:
app: mysql
template:
metadata:
labels:
app: mysql
spec:
containers:
- name: mysql
image: mysql:5.7
env:
- name: MYSQL_DATABASE
valueFrom:
configMapKeyRef:
name: mysql-config
key: MYSQL_DATABASE
Monter une ConfigMap comme fichier
volumes:
- name: config-volume
configMap:
name: redis-config
containers:
- name: redis
volumeMounts:
- name: config-volume
mountPath: /redis-master
Secrets
Les Secrets se manipulent comme des ConfigMaps, mais ils sont encodés en base64 et destinés aux données sensibles : mots de passe, clés privées, certificats, tokens.
Il y a deux façons d'utiliser un Secret :
- Comme variable d'environnement (via
secretKeyRef) - Comme fichier monté en volume (via un volume de type
secret) — peut utilisertmpfspour ne jamais écrire sur disque
Pour définir qui a accès à quels secrets, on utilise le RBAC Kubernetes.
Créer un secret en ligne de commande
# Depuis un fichier
kubectl create secret generic my-cert --from-file=mycert.pem
# Depuis des valeurs littérales
kubectl create secret generic postgres-secret \
--from-literal=POSTGRES_USER=user \
--from-literal=POSTGRES_PASSWORD=password
Les données d'un secret sont encodées en base64 (pas chiffrées — stocker dans etcd chiffré est une configuration séparée).
Utiliser un Secret comme variable d'environnement
env:
- name: POSTGRES_USER
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_USER
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: POSTGRES_PASSWORD
Monter un Secret comme fichier
containers:
- name: mycontainer
volumeMounts:
- name: my-cert
mountPath: /etc/mycert.pem
readOnly: true
volumes:
- name: my-cert
secret:
secretName: my-cert
Contrôleurs alternatifs : Jobs, CronJobs, StatefulSets
Quand utiliser quel contrôleur ?
| Contrôleur | Cas d'usage |
|---|---|
| Deployment | Application stateless, pods interchangeables, ordre de création non important |
| StatefulSet | Application stateful (base de données), identité réseau stable, stockage persistant |
| DaemonSet | Un agent par nœud (monitoring, réseau) |
| Job | Tâche unique ponctuelle (migration de base de données, batch) |
| CronJob | Tâche récurrente planifiée (backup, nettoyage) |
Jobs
Les Jobs sont utiles pour des tâches à exécuter une seule fois. Si vous exécutez une migration de base de données dans un Deployment, dès que la migration se termine, le ReplicaSet va tenter de redémarrer le pod — votre migration tourne en boucle.
Un Job garantit que la tâche s'exécute jusqu'à complétion un nombre défini de fois.
CronJobs
Comme un Job, mais planifié sur un intervalle régulier, avec la syntaxe cron unix.
apiVersion: batch/v1
kind: CronJob
metadata:
name: daily-backup
spec:
schedule: "0 0 * * *" # tous les jours à minuit
jobTemplate:
spec:
template:
spec:
containers:
- name: backup
image: my-backup-image:1.2
command: ["/bin/sh", "-c", "backup.sh"]
restartPolicy: OnFailure
StatefulSets
L'objet StatefulSet est fait pour répliquer des pods dont l'état est important — typiquement des bases de données.
Un StatefulSet fournit :
- Identités stables : les pods sont nommés
web-0,web-1,web-2— le nom ne change pas même si le pod est recréé - Stockage stable et persistant : les volumes liés ne sont pas supprimés quand on supprime le StatefulSet
- Déploiement et scaling ordonnés : déploiement dans l'ordre (
web-0avantweb-1), suppression dans l'ordre inverse - Rolling updates ordonnées
On utilise les StatefulSets quand :
- L'ordre de création des replicas et le nom des pods est important
- L'application écrit dans une base de données (opérations stateful)
Exemple minimal : StatefulSet Redis
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-set
namespace: mynamespace
spec:
serviceName: "redis"
replicas: 2
selector:
matchLabels:
app: redis
template:
metadata:
labels:
app: redis
spec:
containers:
- name: redis
image: redis:latest
ports:
- containerPort: 6379
volumeMounts:
- name: redis-data
mountPath: /data
volumeClaimTemplates:
- metadata:
name: redis-data
spec:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 100Mi
Le volumeClaimTemplates crée automatiquement un PVC par pod : redis-data-redis-set-0, redis-data-redis-set-1, etc.
Stockage et Volumes
Principe
Les conteneurs sont immutables : Kubernetes peut les supprimer et recréer automatiquement. Tout fichier créé pendant l'exécution est perdu. La persistance des données passe par des volumes, montés à un emplacement du système de fichiers du conteneur.
Types de volumes
emptyDir: volume temporaire partagé entre les conteneurs d'un même pod — détruit avec le podconfigMap/secret: monte la configuration ou les secrets comme fichiershostPath: monte un dossier du nœud — à éviter (lie le pod à un nœud spécifique, problèmes de sécurité)persistentVolumeClaim: volume persistant via le système PVC/StorageClass
PersistentVolumeClaim (PVC)
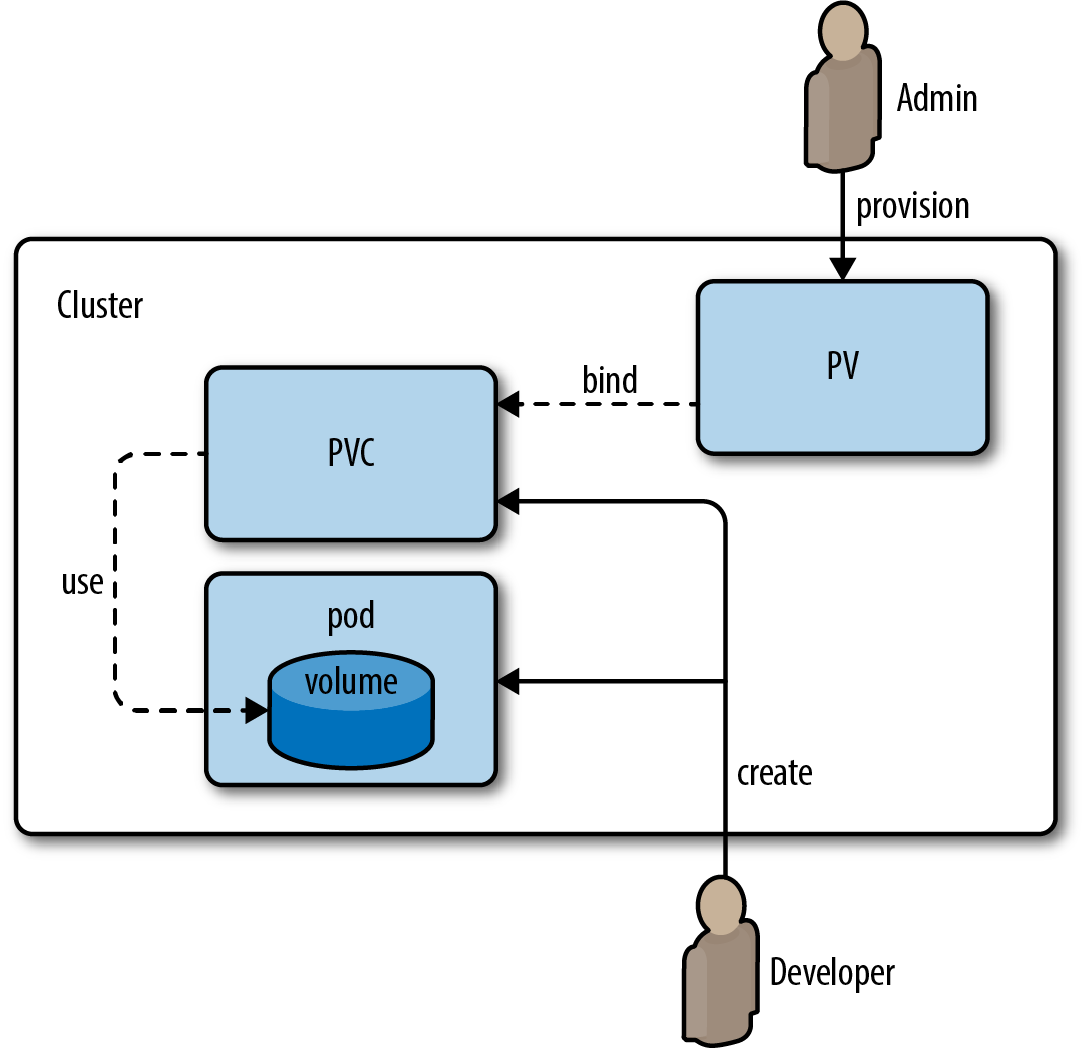
Pour du stockage persistant, le flux est :
- Un pod crée une PersistentVolumeClaim (demande de volume)
- La StorageClass répond en créant un PersistentVolume
- Le PVC et le PV sont liés — le pod peut accéder au volume
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: redis-pvc
namespace: mynamespace
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
Modes d'accès :
ReadWriteOnce(RWO) : un seul nœud peut écrireReadWriteMany(RWX) : plusieurs nœuds peuvent écrire (nécessite un stockage compatible : NFS, Longhorn, Ceph...)
volumes:
- name: redis-storage
persistentVolumeClaim:
claimName: redis-pvc
Commandes kubectl essentielles
# Gérer le namespace courant
kubectl create namespace mynamespace
kubectl config set-context --current --namespace=mynamespace
kubectl config get-contexts
# Inspecter les objets de configuration
kubectl get configmap <nom> -o yaml
kubectl get secret <nom> # valeurs en base64
kubectl describe secret <nom> # affiche les clés (pas les valeurs)
# Inspecter le stockage
kubectl get storageclass # classes de stockage disponibles
kubectl get pvc # PersistentVolumeClaims
kubectl get pv # PersistentVolumes
# Inspecter les services
kubectl get endpoints <service> # IPs des pods backend d'un service
# Exécuter une commande dans un pod
kubectl exec -it <pod> -- /bin/sh
kubectl exec -it <pod> -- env | grep POSTGRES
kubectl exec <pod> -- cat /data/fichier.txt
Le label automatique statefulset.kubernetes.io/pod-name: <pod-name> est ajouté par Kubernetes sur chaque pod d'un StatefulSet. On peut l'utiliser dans un Service selector pour cibler un pod précis.
Transversaux
Requests et limits : réserver des ressources
Définir des requests et limits pour chaque conteneur est indispensable pour partager un cluster correctement.
- Requests : ressources réservées — utilisées par le scheduler pour décider sur quel nœud placer le pod
- Limits : plafond — le conteneur ne peut pas dépasser cette valeur
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Un pod sans request peut se faire déplacer en priorité (basse priorité QoS).
Problème courant : ratio CPU réservé/CPU utilisé trop élevé. Exemple :
- Utilisation CPU globale du cluster : 14%
- Réservation CPU globale : 81%
- Résultat : impossible de scheduler un nouveau pod — le cloud autoscaler ajoute un nœud inutilement
Longhorn : stockage persistant pour clusters on-premise
Longhorn est un opérateur de stockage distribué open-source pour Kubernetes (projet CNCF). Il fournit une StorageClass longhorn qui permet le provisionning dynamique de volumes persistants, y compris en mode ReadWriteMany.
Installation :
sudo apt install nfs-common -y
kubectl apply -f https://raw.githubusercontent.com/longhorn/longhorn/v1.6.0/deploy/longhorn.yaml
Après installation, la StorageClass longhorn est disponible : kubectl get storageclass.
SecurityContext : sécurité des pods
Un securityContext permet de contraindre l'exécution d'un conteneur :
securityContext:
runAsUser: 999
runAsGroup: 999
readOnlyRootFilesystem: true
runAsUser: UID sous lequel le processus s'exécute (éviter root)readOnlyRootFilesystem: système de fichiers du conteneur en lecture seule