Cours Après-midi - Autoscaling, Scheduling & Operators
Scale Up vs Scale Out
| Approche | Description | Usage Kubernetes |
|---|---|---|
| Scale Up | Augmenter les ressources d'un nœud existant (CPU, RAM) | VPA — ajuste les resources par pod |
| Scale Out | Ajouter des nœuds ou pods supplémentaires | HPA — ajoute des replicas ; Cluster Autoscaler — ajoute des nœuds |
Kubernetes utilise principalement le scale out pour gérer les charges de travail.
Horizontal Pod Autoscaler (HPA)
Le HPA ajuste dynamiquement le nombre de replicas d'un déploiement en fonction de métriques (CPU, mémoire, métriques personnalisées).
Mécanismes internes
- Metrics Server : Collecte les métriques d'utilisation des ressources en temps réel
- Contrôleur HPA : Compare les métriques aux seuils définis et décide du scaling
- API Kubernetes : Le contrôleur ajuste le nombre de replicas via l'API
- Stratégies de scaling : Les ajustements sont fluides, avec des cooldown periods
Quickstart
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 80
kubectl get hpa
kubectl describe hpa myapp-hpa
Utilisation d'autres métriques
Au-delà du CPU, il est possible de scaler sur :
- Métriques personnalisées : temps de traitement des requêtes, nombre d'erreurs 500
- Métriques externes : longueur d'une file de messages (RabbitMQ, Kafka)
- Prometheus Adapter : exposition des métriques Prometheus à l'API Kubernetes
Difficultés et pièges
- Faux positifs (flapping) : réaction excessive à des pics temporaires — utiliser
stabilizationWindowSeconds - Délais de scaling : le HPA ne réagit pas instantanément, des périodes de latence sont inévitables
- Requests mal dimensionnées : si les requests sont trop élevées, le HPA peut ne pas scaler même sous charge
- Métriques CPU vs charge réelle : le CPU ne reflète pas toujours l'état applicatif réel
KEDA — Kubernetes Event-Driven Autoscaling
KEDA est un operator CNCF qui étend le HPA natif Kubernetes pour scaler sur n'importe quelle source de métriques : files de messages, bases de données, métriques Prometheus, plannings cron...
Le HPA natif est limité aux métriques CPU et mémoire (ou aux métriques custom via Prometheus Adapter, qui nécessite une configuration complexe). KEDA résout ça en agissant comme un pont : il surveille n'importe quelle source externe et alimente le HPA avec les métriques correspondantes.
Architecture
Source externe KEDA Operator Kubernetes
(RabbitMQ, Kafka, → ScaledObject → HPA (créé auto) → Deployment
Prometheus, cron) surveille et ajuste les
calcule replicas
KEDA ne remplace pas le HPA — il en crée un automatiquement et le pilote. Vous pouvez inspecter ce HPA avec kubectl get hpa.
Le ScaledObject
La CRD centrale de KEDA est le ScaledObject — il déclare ce qu'on scale, les bornes, et les triggers :
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: mon-app-scaledobject
spec:
scaleTargetRef:
name: mon-app # Deployment à scaler
minReplicaCount: 1
maxReplicaCount: 10
pollingInterval: 15 # vérifie la métrique toutes les 15s
advanced:
horizontalPodAutoscalerConfig:
behavior:
scaleDown:
stabilizationWindowSeconds: 300 # attend 5 min avant scale-down
triggers:
- type: cpu
metricType: Utilization
metadata:
value: "50" # scale si CPU moyen > 50%
Quelques scalers notables
| Trigger | Usage |
|---|---|
cpu / memory | Utilisation des ressources (comme le HPA natif) |
kafka | Longueur d'un topic Kafka |
rabbitmq | Longueur d'une queue RabbitMQ |
prometheus | N'importe quelle métrique PromQL |
cron | Scaling planifié (horaires d'ouverture, pics prévisibles) |
redis | Longueur d'une liste Redis |
Installation
helm repo add kedacore https://kedacore.github.io/charts
helm install keda kedacore/keda --namespace keda --create-namespace
Une fois installé, KEDA déploie trois composants : l'operator, le metrics API server, et l'admission webhook. Les six CRDs installées sont visibles avec kubectl get crd | grep keda.
Vertical Pod Autoscaler (VPA)
Le VPA ajuste automatiquement les requests et limits CPU/mémoire des pods en fonction des besoins réels.
Contrairement au HPA qui ajoute des pods, le VPA modifie les ressources allouées à chaque pod individuel.
Fonctionnement
- Surveillance : Collecte continue de l'utilisation CPU/mémoire des pods
- Recommandations : Génère des recommendations de
requestsetlimitsoptimales - Application : En mode
Auto, redémarre les pods avec les nouvelles allocations
Modes de fonctionnement
| Mode | Comportement |
|---|---|
Off | Calcule les recommandations sans les appliquer |
Initial | Applique les recommandations uniquement à la création des pods |
Auto | Applique les recommandations en redémarrant les pods |
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: myapp-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: myapp
updatePolicy:
updateMode: "Auto"
Limites du VPA
- Redémarre les pods pour appliquer les changements — interruption de service possible
- Ne peut pas être utilisé en même temps que le HPA sur les mêmes métriques (CPU/mémoire)
- Recommandé pour les workloads stables dont les ressources sont difficiles à dimensionner manuellement
Cluster Autoscaler
Le Cluster Autoscaler ajuste automatiquement le nombre de nœuds du cluster en fonction des besoins en ressources.
Fonctionnement
- Surveillance : Détecte les pods qui ne peuvent pas être schedulés (ressources insuffisantes)
- Ajout de nœuds : Ajoute des nœuds pour satisfaire les demandes
- Suppression de nœuds : Supprime les nœuds sous-utilisés pour optimiser les coûts
Problèmes récurrents
- Métriques incorrectes → décisions de scaling inappropriées
- Changements d'offre du cloud provider / mauvaises configurations
- Indisponibilité du provider → pas de machines disponibles
- Quotas du provider → impossibilité d'ajouter des ressources
- Latences : incohérence temporelle entre demande et obtention
- Pods avec PVC → éviction impossible, nœuds mal exploités
Right-sizing et gestion des coûts
Le right-sizing consiste à aligner les requests et limits déclarées sur la consommation réelle des workloads.
Un cluster mal dimensionné présente typiquement ce paradoxe : faible utilisation réelle (10-15% CPU) mais forte réservation (70-80%). Le scheduler ne peut plus placer de nouveaux pods — le Cluster Autoscaler ajoute des nœuds inutilement, la facture cloud monte.
Identifier les workloads mal dimensionnés
# Consommation réelle des pods (nécessite metrics-server)
kubectl top pods -A --sort-by=cpu
kubectl top pods -A --sort-by=memory
# Comparer requests vs utilisation dans Grafana
# Métrique : container_cpu_usage_seconds_total vs kube_pod_container_resource_requests
Le ratio à surveiller : utilisation réelle / requests déclarées. Un ratio < 20% est un signal fort de sur-provisionnement.
VPA en mode Off : recommandations sans action
Le VPA en mode Off observe la consommation sur la durée et génère des recommandations sans jamais modifier les pods. C'est l'outil de diagnostic idéal.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: myapp-vpa-audit
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: myapp
updatePolicy:
updateMode: "Off" # recommandations uniquement, aucun redémarrage
kubectl describe vpa myapp-vpa-audit
# Affiche : Lower Bound, Target, Upper Bound pour CPU et mémoire
Goldilocks : tableau de bord des recommandations VPA
Goldilocks (Fairwinds) déploie un VPA en mode Off sur chaque Deployment du namespace et expose une interface web avec les recommandations.
helm repo add fairwinds-stable https://charts.fairwinds.com/stable
helm install goldilocks fairwinds-stable/goldilocks --namespace goldilocks --create-namespace
# Activer sur un namespace
kubectl label namespace <namespace> goldilocks.fairwinds.com/enabled=true
Bonne pratique
- Faire tourner VPA/Goldilocks en mode
Offpendant 1 à 2 semaines pour couvrir les cycles de charge - Ajuster les requests en visant le P95 de la consommation observée
- Recalibrer après chaque changement de charge significatif (nouvelle fonctionnalité, montée en trafic)
Eviction, Cordon et Drain
Cordon et Drain : préparer la maintenance d'un nœud
Avant de mettre un nœud en maintenance (mise à jour OS, remplacement matériel), il faut l'évacuer proprement sans interrompre les applications.
kubectl cordon marque un nœud comme non-schedulable : aucun nouveau pod ne sera placé dessus, mais les pods existants continuent de tourner.
kubectl cordon <node-name>
# Le nœud passe en état "SchedulingDisabled"
kubectl get nodes
kubectl drain va plus loin : il expulse tous les pods du nœud (sauf les DaemonSets), puis le marque comme non-schedulable. Les pods sont recréés ailleurs par leurs contrôleurs (Deployment, StatefulSet...).
kubectl drain <node-name> --ignore-daemonsets --delete-emptydir-data
# --ignore-daemonsets : ne pas bloquer sur les DaemonSets (ils ne peuvent pas être déplacés)
# --delete-emptydir-data : accepter la perte des volumes emptyDir
Après la maintenance, remettre le nœud en service :
kubectl uncordon <node-name>
Un pod sans contrôleur (pod nu) bloque le drain par défaut — utiliser
--forcepour l'expulser, mais il sera définitivement perdu.
Eviction : récupérer des ressources sous pression
L'eviction est le mécanisme par lequel le kubelet expulse automatiquement des pods quand un nœud manque de ressources (mémoire, disque, PID).
Conditions surveillées par le kubelet :
| Condition | Déclencheur |
|---|---|
MemoryPressure | Mémoire disponible sous le seuil |
DiskPressure | Espace disque ou inodes insuffisants |
PIDPressure | Nombre de processus trop élevé |
Quand une condition est active, le kubelet choisit quels pods expulser en fonction de leur classe QoS.
Classes QoS et ordre d'éviction
La façon dont on configure les requests et limits détermine la classe QoS du pod, qui influe directement sur l'ordre d'éviction en cas de pression mémoire sur un nœud :
| Classe | Condition | Éviction |
|---|---|---|
| Guaranteed | Toutes les requests = toutes les limits (CPU et RAM) | Derniers évincés |
| Burstable | Au moins une request ou limit définie, mais pas Guaranteed | Évincés en second |
| Best Effort | Aucune request ni limit définie | Premiers évincés |
# Guaranteed : request == limit pour CPU et mémoire
resources:
requests:
cpu: "500m"
memory: "128Mi"
limits:
cpu: "500m"
memory: "128Mi"
Un pod sans aucune request ni limit (Best Effort) peut se faire évincer même s'il est healthy.
Taints, Tolerations et Affinity
Principe Taints / Tolerations
Un Taint est appliqué sur un nœud pour le rendre sélectif — il repousse tous les pods qui ne déclarent pas de Toleration correspondante.
# Appliquer un taint sur un nœud (ex : nœud avec GPU)
kubectl taint nodes mynode needgpu=true:NoSchedule
# Pod qui tolère ce taint — sera schedulé sur le nœud GPU
spec:
containers:
- name: deepdata
image: deepdata:1.0
tolerations:
- key: "needgpu"
operator: "Equal"
value: "true"
effect: "NoSchedule"
Effets possibles : NoSchedule (pas de nouveau scheduling), PreferNoSchedule (évité si possible), NoExecute (expulse les pods existants).
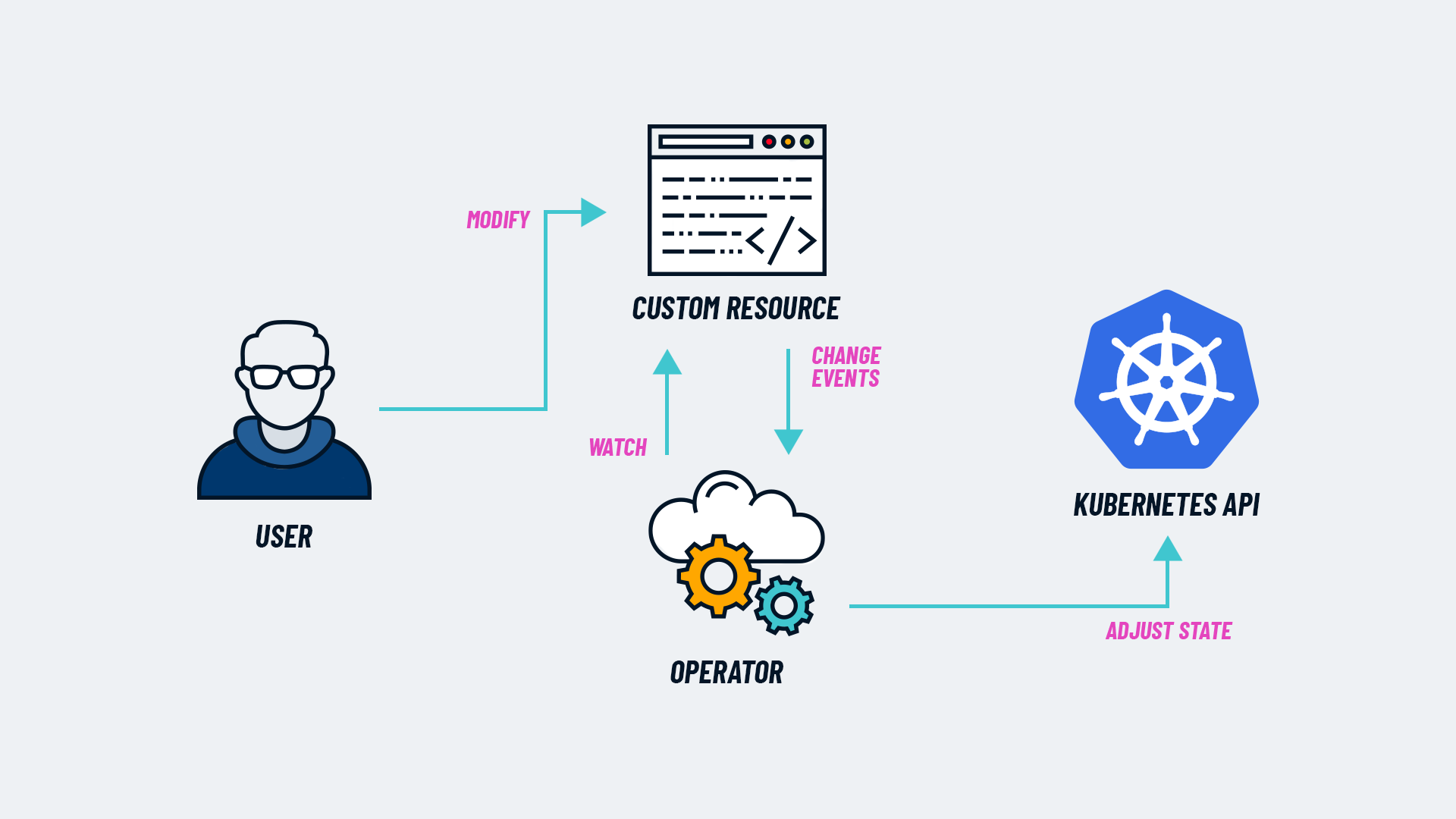
Le pattern Operator

Un Controller est un processus qui surveille l'état du cluster et applique des modifications pour atteindre l'état souhaité.
Un Operator étend ce concept en encapsulant la logique métier nécessaire pour gérer des applications spécifiques : sauvegardes, mises à jour, configurations personnalisées.
Exemple : Elastic Cloud on Kubernetes (ECK) gère le cycle de vie complet d'un cluster Elasticsearch.
La boucle de réconciliation
Utilisateur définit l'état désiré (YAML)
│
▼
API Server enregistre l'état désiré
│
▼
Controller surveille l'état actuel
│
▼
Différence détectée ?
├── Non → Continue à surveiller
└── Oui → Prend des mesures correctives
│
▼
Mise à jour de l'état dans l'API Server
│
▼
Cycle continue...
Déclenchement des contrôleurs
- kube-controller-manager : gère les contrôleurs intégrés (ReplicaSet, Deployment, etc.)
- Contrôleurs personnalisés : s'exécutent en tant que pods, surveillent des CRDs
- Informer Framework (
client-go) : abstrait la surveillance des ressources, gère le cache - WorkQueue : file de travail pour traiter les événements en ordre
Custom Operators avec Kubebuilder
Kubebuilder est le framework officiel Go pour créer des operators Kubernetes.
Prérequis
- Go v1.20+
- Docker v17.03+
- kubectl v1.11.3+
- Accès à un cluster Kubernetes
Quickstart
# Installer Kubebuilder
curl -L -o kubebuilder "https://go.kubebuilder.io/dl/latest/$(go env GOOS)/$(go env GOARCH)"
chmod +x kubebuilder && mv kubebuilder /usr/local/bin/
# Créer un projet
mkdir -p ~/projects/monoperator && cd ~/projects/monoperator
kubebuilder init --domain mon.domaine --repo mon.domaine/monoperator
# Créer une API (CRD + Controller)
kubebuilder create api --group webapp --version v1 --kind MonApp
# Installer les CRDs dans le cluster
make install
# Lancer le contrôleur localement
make run
# Builder et déployer l'image
make docker-build docker-push IMG=<registry>/monoperator:tag
make deploy IMG=<registry>/monoperator:tag
Les CRDs
Les CRDs permettent de définir de nouveaux types de ressources gérés par l'Operator :
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: drinks.example.com
spec:
group: example.com
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
name:
type: string
scope: Namespaced
names:
plural: drinks
singular: drink
kind: Drink
Bonnes pratiques Operator
- Ne pas s'exécuter en tant que
root— utiliser un ServiceAccount dédié - Ne pas auto-enregistrer les CRDs — les gérer séparément
- Ne pas installer d'autres Operators — déléguer à OLM (Operator Lifecycle Manager)
- Écrire des informations de statut significatives sur les Custom Resources
- Supporter les mises à jour depuis une version précédente
- Utiliser des webhooks de conversion pour les changements d'API/CRDs
- Valider les CR via OpenAPI / Admission Webhooks
Gestion des versions de CRD
Votre operator va évoluer — il faut gérer la compatibilité ascendante et descendante.
Trois approches :
- Un contrôleur par version de CRD : simple à gérer, complexe à déployer
- Version unique : un contrôleur avec des conditions par version
- Approche hybride : contrôleur principal pour les versions stables, contrôleurs additionnels pour les versions en développement
Les webhooks de conversion traduisent automatiquement les anciennes versions en nouvelles — recommandé par la documentation officielle Kubernetes.
Exemple d'Operator réel : Kubi (k8s + LDAP)
Kubi est une solution d'accès et de gestion de clusters Kubernetes intégrant Active Directory.
Source : https://github.com/ca-gip/kubi
- Authentification : Jetons JWT temporaires signés par clé privée, vérifiés par clé publique
- Autorisation : Rôles et permissions définis dans Active Directory
- Composants : Serveur Kubi (génère les jetons) + Client Kubi (CLI)
Exercice d'analyse :
- Où sont les CRDs ? Que définissent-elles ?
- Que contient le Makefile ? Quelles sont les cibles ?
- Voyez-vous un contrôleur ? Comment fonctionne-t-il ?
- Que pensez-vous de la structure et de la documentation ?