Cours optionnel - Principes de conception et architecture détaillée de Kubernetes
Le concept de configuration déclarative est l'un des principaux fondements du développement de Kubernetes : un utilisateur déclare un état souhaité du système pour produire un résultat.
Exemple : "Je veux qu'il y ait 3 instances de mon serveur en fonctionnement à tout moment". Kubernetes, prend cette information déclarative et se charge de la rendre effective.
La puissance de cette approche déclarative (qui est plus complexe au départ que l'approche impérative) est qu'en donnant au système une déclaration de l'état que vous souhaitez plutôt qu'une série d'instructions de bas niveau vous lui permettez de prendre des mesures autonomes. Il peut mettre en œuvre des comportements automatiques pour se réparer lui-même sans vous réveiller au milieu de la nuit.
Et ce cadre déclaratif de haut niveau peut servir de base à une automatisation extrêmement dynamique de nombreuses tâche opérationnelles grâce aux opérateurs.
Contrôleurs et boucles de réconciliation
Kubernetes est basé une approche décentralisée (plutôt que monolithique) : Au lieu d'un unique contrôleur monolithique, il est composé d'un grand nombre de contrôleurs, chacun effectuant sa propre boucle de réconciliation indépendante pour autocorriger l'état du système.
Chaque boucle individuelle n'est responsable que d'une petite partie du système (par exemple, la mise à jour de la liste des
endpointspour une ressourceService/Endpointparticulière)Chaque contrôleur
ignore l'état global du systèmece qui rend l'ensemble beaucoupplus stable: chaque contrôleur n'est pas affecté par des problèmes ou des changements sans rapport direct avec lui.Un inconvénient de cette approche distribuée est que le comportement global peut être
plus difficile à comprendre, car il n'y a pas d'endroit unique où chercher une explication : il est nécessaire d'examiner le fonctionnement coordonné d'un grand nombre de processus indépendants.
Une boucle de réconciliation répète sans arrêt les étapes suivante :
- Obtenir l'état souhaité.
- Observer le système.
- Trouver les différences entre l'observation et l'état souhaité.
- Prendre des mesures pour que le système corresponde à l'état souhaité.
Concrêtement : "Je veux trois instances de ce serveur " => Le contrôleur de réplication (des replicatsets) prend cet état souhaité observe ensuite le système => il y a actuellement trois instances du conteneur de serveur => Le contrôleur
Le contrôleur constate la différence entre l'état actuel et l'état souhaité (un serveur manquant) => il prend des mesures pour que l'état actuel corresponde en créant un quatrième conteneur de serveur
Regroupement dynamique par labels
Le défi dans cette configuration de contrôleurs dynamiques et distribués est de déterminer l'ensemble des ressources auxquelles la boucle de réconciliation doit prêter attention. Lorsqu'il s'agit de regrouper des éléments dans un ensemble deux approches possibles : le regroupement explicite/statique ou implicite/dynamique.
Avec le regroupement explicite chaque groupe est défini par une liste concrète "Les membres du groupe sont A, B, et C". Mais cette méthode ne peut pas répondre facilement à un système qui change de façon dynamique.
Avec les groupes implicites, au lieu d'une liste de membres, le groupe est défini par une déclaration telle que "Les membres du groupe sont les personnes qui portent des vêtements en coton".Ils sont implicites récupérés en évaluant la définition du groupe par rapport à un ensemble de personnes présentes.
Comme l'ensemble des objets du groupe peut toujours changer, la composition du groupe est dynamique et changeante. Bien que cela puisse introduire de la complexité de devoir évaluer à chaque fois les membres, cette méthode est beaucoup plus flexible et stable dans un environnement changeant sans nécessiter d'ajustements constants.
Dans Kubernetes chaque objet d'API peut avoir un nombre arbitraire de "labels" clé/valeur qui sont associés aux objets d'API. Vous pouvez ensuite utiliser une requête ou un sélecteur de labels pour identifier un ensemble logique d'objets correspondant à cette requête.
kubectl get service --selector='app.kubernetes.io/name=monapp'kubectl get node --selector='!node-role.kubernetes.io/master:
La documentation suggère aussi un modèle de labels standard pour vos application pour favoriser l'interopérabilité avec plusieurs outils:
https://kubernetes.io/docs/concepts/overview/working-with-objects/common-labels/
Pour écrire des chart Helm il est également important (bien que facultatif) de respecter son standard d'étiquettes.
Retour détaillé sur les composants du Control Plane
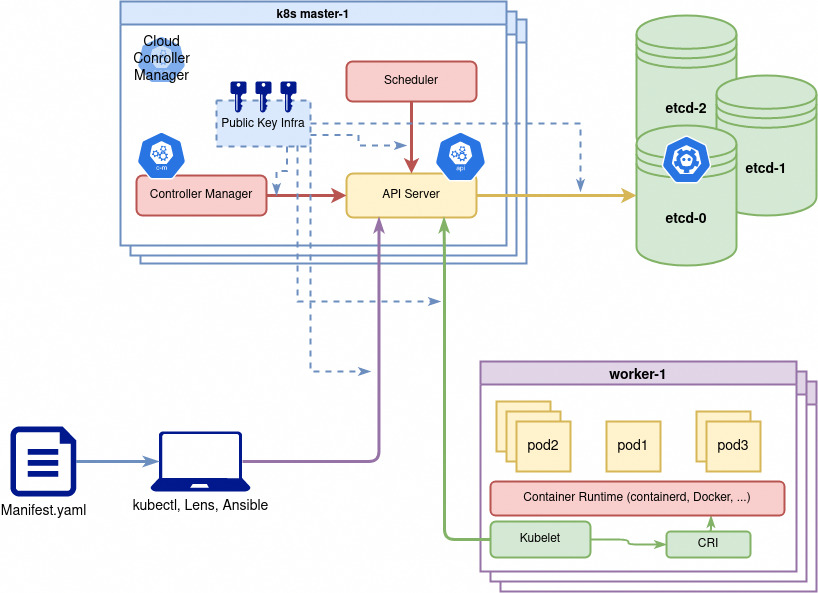
Kubernetes adhère à la philosophie (Unix) de modularité de petits composants qui font bien leur travail. Kubernetes n'est pas une application d'un seul tenant qui implémente les diverses fonctionnalités du système dans un seul binaire. Il s'agit plutôt d'une collection de différentes applications qui travaillent toutes ensemble, en grande partie en s'ignorant les unes les autres, pour mettre en œuvre le système global.
Même lorsqu'il existe un binaire (par exemple, le controller manager) qui regroupe un grand nombre de fonctions différentes, ces fonctions sont maintenues indépendantes les unes des autres dans ce binaire. Elles sont compilées ensemble pour faciliter la tâche de déploiement et de gestion réseaux de Kubernetes.
etcd
Le composant etcd est au cœur de tout cluster Kubernetes. Il s'agit d'un key/value store où tous les objets d'un cluster Kubernetes sont conservés.
Les serveurs etcd utilisent un algorithme de consensus distribué Raft qui garantit que même si un des serveurs tombe en panne, la réplication est suffisante pour maintenir les données stockées et pour récupérer automatiquement les données lorsqu'un serveur etcd redevient sain et se réintègre au cluster.
Les serveurs etcd fournissent également deux autres fonctionnalités importantes dont Kubernetes fait un usage intensif:
La
concurrence optimiste. Chaque valeur stockée dans etcd a une version de ressource correspondante. Lorsqu'une paire clé-valeur est écrite sur un serveur etcd, elle peut être conditionnée à une version de ressource particulière. Cela signifie qu'en utilisant etcd, vous pouvez implémenter le principe decompare and swap, qui est au cœur de tout système de concurrence. La comparaison et l'échange permettent à un utilisateur de lire une valeur et de la mettre à jour en sachant qu'aucun autre composant du système n'a également mis à jour cette valeur. Ces assurances permettent au système d'avoir en toute sécurité plusieurs threads manipulant des données dans etcd sans avoir besoin de recourir à despessimistic locks, ce qui peut réduire de manière significative le débit du serveur. L'idée qui sous-tend la concurrence optimiste est la capacité d'effectuer la plupart des opérations sans utiliser de verrous (concurrence pessimiste) et, au lieu de cela, de détecter l'apparition d'une écriture concurrente et de rejeter la dernière des deux écritures concurrentes.Le protocole
watch. L'intérêt dewatchest qu'il permet aux clients de surveiller efficacement les changements dans lekey/value storepour un grand ensemble de valeurs. Par exemple, tous les objets objets d'unNamespacesont stockés dans un répertoire dans etcd. L'utilisation d'une veille permet à un client d'attendre et de réagir efficacement aux changements dans ceNamespacesans avoir à interroger en permanence le serveur etcd.
L'API comme gateway pour toutes les interactions
Un autre concept structurel central de Kubernetes est que toutes les interactions entre les composants sont pilotées à travers une API centralisée : l'API que les composants utilisent est exactement la même API que celle utilisée par tous les autres utilisateurs du cluster:
Donc aucune partie du système n'est plus privilégiée et aucun composant n'a accès à directement aux données internes.
Et aussi chaque composant peut être remplacé pour une implémentation alternative sans avoir à reconstruire les composants de base. Même le
Schedulerpeut être échangé ou simplement augmenté par des implémentations alternatives.
Le serveur API implémente une API RESTful en HTTP, exécute toutes les opérations d'API et est responsable du stockage des objets d'API dans un backend de stockage persistant, généralement etcd.
Il sert de médiateur pour toutes les interactions entre les clients et les objets API stockés dans etcd. Par conséquent, il est le point de rencontre central de tous les différents composants.
Kubernetes API et extension par APIgroups
Tous les types de resources Kubernetes correspondent à un morceau (un sous arbre) d'API REST de Kubernetes. Ces chemins d'API pour chaque ressources sont classés par groupe qu'on appelle des apiGroups:
- On peut lister les resources et leur groupes d'API avec la commande
kubectl api-resources -o wide. - Ces groups correspondent aux préfixes indiqué dans la section
apiVersiondes descriptions de ressources. - Ces groupes d'API sont versionnés sémantiquement et classés en
alphabetaetstable.betaindique déjà un bon niveau de stabilité et d'utilisabilité et beaucoup de ressources officielles de kubernetes ne sont pas encore en api stable. Exemple: lesCronJobsviennent de se stabiliser au début 2021. - N'importe qui peut développer ses propres types de resources appelées
CustomResourceDefinition(voir ci dessous) et créer unapiGrouppour les ranger.
Documentation: https://kubernetes.io/docs/reference/using-api/
Les routes web de et la découverte de l'API
L'API a des routes systématiques pour les ressources :
Voici les composants des deux chemins différents pour les types de ressources namespaced :
/api/v1/namespaces/<namespace-name>/<resource-type-name>/<resource-name>./apis/<api-group>/<api-version>/namespaces/<namespace-name>/<resource-type-name>/<resource-name>.
Voici les composants des deux chemins différents pour les types de ressources sans namespace :
/api/v1/<nom-de-la-ressource>/<nom-de-la-ressource>/apis/<api-group>/<api-version>/<resource-type-name>/<resource-name>
Maintenant, nous aimerions explorer l'API et voir comment elle donne des informations pour sa propre exploration. Pour explorer une API REST, l'outil classique curl peut suffire.
Pour faciliter l'exploration du serveur API, exécutez l'outil kubectl en mode proxy pour exposer un serveur API non authentifié sur localhost:8001 en utilisant la commande suivante : kubectl proxy
Ensuite pour voir comment l'API vous donne de nombreuses informations comme toutes les ressources dans chaque api-group vous pouvez lancer : curl localhost:8001/api ou curl localhost:8001/api/v1
Pour accéder à la page web pour l'ensemble des spécifications de l'api (comme tout point de terminaison swagger/openAPI), ouvrez dans un navigateur : localhost:8001/openapi/v2
Vie d'une requête
Pour mieux comprendre ce que fait le serveur d'API pour chacune de ces différentes demandes, nous allons décomposer et décrire le traitement d'une seule demande au serveur d'API.
Authentification
La première étape du traitement des demandes est l'authentification, qui établit l'identité associée à la demande. Le serveur API prend en charge plusieurs modes d'authentification : certificat x509, Token ou backend d'identité principalement. voir cours sécurité.
RBAC/Autorisation
Après que le serveur API ait déterminé l'identité d'une requête, il passe à l'autorisation de celle-ci avec RBAC
Contrôle d'admission
Une fois qu'une demande a été authentifiée et autorisée, elle passe au contrôle d'admission. Le contrôle d'admission détermine si la demande est bien formée (syntaxe) et applique éventuellement des modifications à la demande avant qu'elle ne soit traitée. On peut ajouter des plugin pour l'admission
Si un contrôleur d'admission trouve une erreur, la requête est rejetée. Si la demande est acceptée, la demande transformée est utilisée à la place de la demande initiale. Les contrôleurs d'admission sont appelés en série, chacun recevant le résultat du précédent.
C'est un méchanisme très général utilisé par exemple pour ajouter des valeurs par défaut aux objets, appliquer une pod security policy etc.
Requêtes spécialisées
En plus des requêtes RESTful standard, le serveur API dispose d'un certain nombre de modèles de requête spécialisés qui fournissent des fonctionnalités étendues aux clients :
/proxy, /exec, /attach, /logs.
La première catégorie importante d'opérations est constituée par les connexions ouvertes, de longue durée, au serveur d'API. Ces requêtes fournissent des données en continu plutôt que des réponses immédiates.
logs est la demande de streaming la plus facile à comprendre car elle laisse simplement la demande ouverte et fournit plus de données en continu. Les autres opérations tirent parti du protocole WebSocket pour la diffusion bidirectionnelle des données.
En plus de ces flux, le serveur API Kubernetes introduit en fait un protocole de flux multiplexé supplémentaire. La raison en est que, pour de nombreux cas d'utilisation, il est très utile que le serveur API soit capable de gérer plusieurs flux d'octets indépendants. Prenons, par exemple, l'exécution d'une commande dans un conteneur. Dans ce cas, il y a en fait trois flux qui doivent être gérés (stdin, stderr et stdout).
Opérations Watch
En plus des données en continu, le serveur API prend en charge une API pour surveiller les ressources. Ainsi, au lieu d'interroger l'API à intervalle régulier pour détecter d'éventuelles mises à jour, ce qui introduit soit une charge/latence supplémentaire, le mode watch permet à un utilisateur d'obtenir des mises à jour à faible latence avec une seule connexion en ajoutant le paramètre de requête ?watch=true.
Boucle de controlle de l'API pour les CRD
Les définitions de ressources personnalisées (CRD) sont des objets API dynamiques qui peuvent être ajoutés à un serveur API en cours d'exécution. Étant donné que l'acte de création d'une CRD crée de nouveaux chemins HTTP que le serveur d'API doit savoir comment ajouter ces chemins et implémente pour cela un contrôleur avec un boucle de contrôle.
Journaux d'audit
/var/log/kubernetes/kube-apiserver.log traditionnellement.
Les journaux d'audit sont destinés à permettre à un administrateur de serveur de récupérer "forensically" l'état du serveur et la série d'interactions avec les clients qui ont abouti à l'état actuel des données dans l'API Kubernetes. Par exemple, il permet à un utilisateur de répondre à des questions telles que : "Pourquoi ce ReplicaSet a-t-il été mis à l'échelle à 100 ? ", " Qui a supprimé ce Pod ? ", entre autres. Les journaux d'audit peuvent être poussés dans un backend spécifique (SIEM ?) pour stockage et analyse
En utilisant --v sur le serveur API, vous pouvez ajuster le niveau de verbosité de la journalisation (defaut --v=2).
En plus du débogage du serveur d'API via les journaux, il est également possible de déboguer les interactions avec le serveur d'API, via l'outil de ligne de commande kubectl. Comme le serveur d'API, l'outil de ligne de commande kubectl enregistre les journaux via le paquet github.com/golang/glog et prend en charge l'indicateur de verbosité --v. Définir la verbosité au niveau 10 (--v=10)
Scheduler : assigner des pods aux noeuds
Avec etcd et le serveur API fonctionnant correctement, un cluster Kubernetes est, d'une certaine manière, fonctionnellement complet. Avec seulement ces deux composants, vous pouvez créer tous les différents objets de l'API, tels que Deployments et Pods. Cependant, en testant cela on peut se rendre compte que les pods ne sont jamais exécutés.
En effet, trouver un emplacement pour l'exécution d'un Pod est le travail du scheduler de Kubernetes. Il scanne le serveur d'API à la recherche de Pods non programmés et détermine ensuite les meilleurs nœuds sur lesquels les exécuter.
Le scheduler va pour cela cartographier en temps réel les ressources encore disponible sur les noeuds, les resources demandées par les pods, les étiquettes de caractéristiques des noeuds appelées Taints, et autres contraintes géographiques des pods comme les Affinity, Anti-affinity ainsi que contraintes de volume etc.
Controller Manager : les boucles de réconciliations
Une fois qu'etcd, le serveur API et le scheduler sont opérationnels, vous pouvez créer des pods et les voir positionnes et exécutés sur les nœuds, mais vous constaterez que les ReplicaSets, les Deployment et Services ne fonctionnent pas . Cela est dû au fait que toutes les boucles de contrôle de réconciliation nécessaires à leur mise en œuvre ne sont pas actuellement en cours d'exécution. C'est le travail du Controller Manager. Il regroupe de nombreuses boucles de contrôle/réconciliation différentes nécessaires au fonctionnement de la plupart des objects auto-piloté/auto-réparant (selfhealing) ou simplement dynamiques du cluster.
Composants des nœuds worker
Kubelet
Le kubelet est l'agent de base pour tous les serveur d'un cluster Kubernetes qui doivent exécuter des conteneurs. Il est nécessaire installé directement sous forme de binaire car il est lui-même en charge des conteneurs. Il est l'élément qui relie le CPU, le disque et la mémoire disponibles d'un nœud au cluster : il communique avec le serveur API pour pour définir et démarrer les conteneurs qui à exécuter sur son nœud.
Le kubelet communique également l'état de ces conteneurs au serveur API afin que d'autres boucles de contrôle de réconciliation puissent observer leur état à tout moment. Il est également en charge de la vérification de l'état de santé et du redémarrage des conteneurs.
Comme il est assez inefficace d'envoyer toutes les informations sur l'état de santé vers le serveur API, le kubelet court-circuite cette interaction API et exécute lui-même la boucle de réconciliation. Ainsi, si un conteneur exécuté par le kubelet s'arrête ou échoue a son healthcheck, le kubelet le redémarre tout en communiquant cet état de santé (et le redémarrage) à l'API.
kube-proxy et KubeDNS
Voir la partie réseau avancé.
Kubernetes Metric Server remplacement de heapster
Il s'agit d'un autre composant nécessairement binaire (non conteneurisé) qui est chargé de collecter des mesures telles que l'utilisation du CPU, du réseau et du disque de tous les conteneurs s'exécutant dans le cluster Kubernetes. Son objectif est d'être plus réactif que le monitoring classique en mode pull et de fournir les données de base pour gérer la mise à l'échelle automatique des Pods (pour alimenter la boucle de réconciliation de l'autoscaler HorizontalPodAutoscaler). Cet objet peut, par exemple, automatiquement augmenter la taille d'un Deployment lorsque l'utilisation du CPU des containers du déploiement dépasse 80 %.