Jour 1 - Après Midi
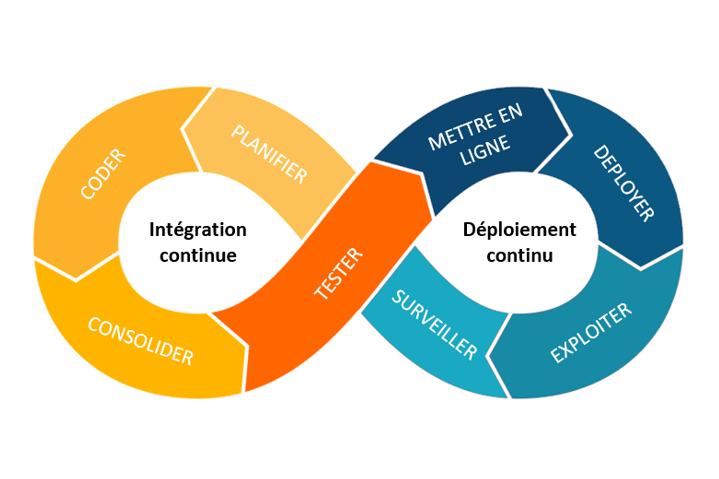
La problématique universelle d'exécution des applications
Depuis l’époque des mainframes, il faut déployer du code en production. Les développeurs écrivent l’application, les équipes d’exploitation la font tourner.
Les différences d’environnements ou de dépendances engendrent souvent des écarts entre ce qui fonctionne en développement et ce qui échoue en production.
L’automatisation a émergé pour réduire ces écarts. Les pipelines de CI/CD outillent ce déploiement automatique, de la construction à la mise en production.
Une petite histoire de l'automatisation du déploiement
On va voir les problèmes de déploiement qui ont amené aux solutions Docker via l'évolution de la question éternelle.
(Dev) - Comment je déploie mon code sur le serveur de prod ?
(Ops) - Comme tu veux, mais pas le vendredi.
À travers quelques exemples et quelques périodes
- FTP (avant 2000)
- SSH + GIT (2009)
- Provisioning & IAC (2010)
- Capistrano (2012)
- Devops (2014)
- 12 factors app / Heroku (2015)
- docker (2016)
- k8s (2018)
Ces dates et ces expériences sont liées à mon expérience.
Par exemple Capistrano est né en 2006, mais ce n'est pas arrivé tout de suite.
Idem, le Devops est né en 2008, mais n'est pas devenu reconnu de suite.
Les contraintes du déploiement et les solutions actuelles
Les applications, en particulier pour le web, ont des contraintes à gérer
- versions du code
J'ai codé une nouvelle fonctionnalité, comment j'intègre ça en prod ?
- différents environnements (dev, prod)
J'ai testé sur la dev, on le passe en prod ?
- fichiers de configuration par environnement
Qui connaît le mot de passe de la DB de prod ?
- dépendances internes (ex: librairies, modules)
Comment j'intègre en prod la librairie qui lit des fichiers Excel ?
- dépendances externes (ex: bases de données)
J'ai ajouté un redis pour stocker du cache, comment on déploie ça en prod ?
- options de lancement du process (options, variables)
Tu savais pas que l'appli crash sans l'option
-XX:+UseZGC? - processus de mise à jour (sauvegarde, retour en arrière)
La nouvelle version de la DB marche pas avec l'ancienne version du code, on fait quoi ?
On va voir comment, aujourd'hui, on a progressé dans la résolution de ces problèmes :
- Les différents environnements utilisent les mêmes images
- Chaque image docker correspond à un état du code dans git
- Les options de configuration par environnement sont dans l'image docker
- Les dépendances internes sont dans l'image docker
- Les options de lancement du code sont dans l'image docker
- La mise à jour est gérée par un orchestrateur
- Les dépendances externes sont manifestées auprès d'un orchestrateur
- Les backups sont automatisés par l'orchestrateur
- Les changements importants de la base de donnée sont découplés du code
Comment on en est arrivé là ?
FTP (avant 2000)
On utilise une application bureau pour mettre à jour le code en fonction des modifications faites sur le poste, fichier par fichier.
- Tous les désavantages qu'on peut imaginer
SSH + GIT (2009)
On stocke les versions du code dans GIT et on se connecte sur le serveur de prod pour faire un pull.
- Au moins on peut revenir en arrière sur le code
Provisioning & IAC (2010)
On peut déployer de nouvelles machines avec les logiciels et le code.
- On a une reproductibilité des environnements d'exécution
Capistrano (2012)
Un gestionnaire de mise à jour capable d'orchestrer les mises à jour avec des backups et des versions.
- Automatisation mais pas de reproductibilité simple
factors app / Heroku (2015)
12 contraintes concernant le déploiement qui visent à les micro services et la croissance.
- Règles / bonnes pratiques concernant le code, les dépendances, la configuration, et autres
k8s (2018)
Une architecture modulaire complexe pour exécuter les applications dans des environnements sécurisés
- Le déploiement devient un objet en soi, au coeur de toute un système complexe mais qui permet de gérer tous ces problèmes.
L'émergence du modèle GitOps
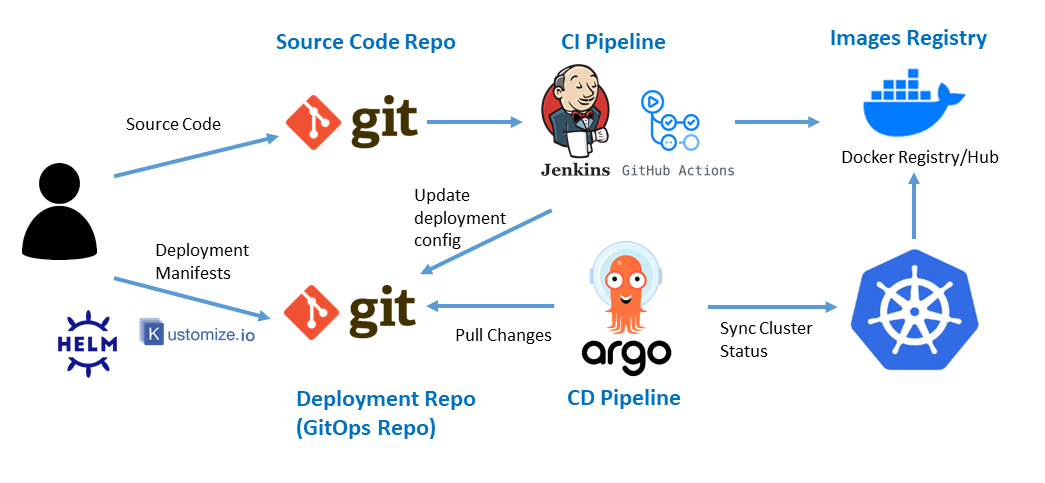
L'approche GitOps vise à simplifier la chaîne des actions requises pour le Déploiement Continu.
L'approche GitOps repose sur l'utilisation de référentiels Git comme unique source de vérité pour distribuer l'infrastructure en tant que code.
Chaque état de l'infrastructure correspond à un état précis du code du projet de déploiement.
Un opérateur Kubernetes spécifique comme ArgoCD se charge de détecter les changements dans le code et aligner automatiquement l'infrastructure avec le code.
Avantages :
- Déclaration d'application côté Kubernetes, ce qui offre une cohérence visuelle supérieure au namespace
- Standardisation du déploiement des applications
- Visibilité des changements via IAC et contrôle de versions Git
- Simplification des échanges : le cluster Kubernetes est autonome pour lancer les rotations de version
Coûts, risques et gouvernance
Budgétiser les runners, le stockage des images et les ressources cloud.
Limiter l’accès aux stages critiques (production) avec des règles d’approbation.
Centraliser ou séparer la logique de CD selon la taille de l’équipe et la complexité du projet.
Fondamentaux du Déploiement Continu avec Docker Compose
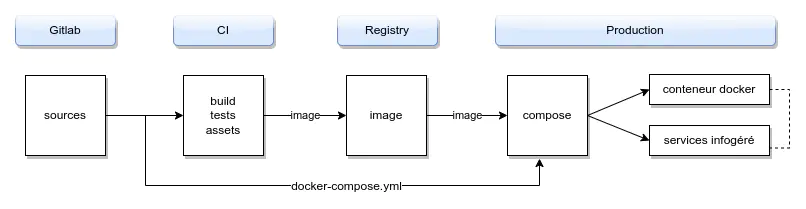
Principes et différences entre CI et CD**
Le CD prolonge la CI en automatisant le déploiement.
Les environnements (dev, staging, production) permettent de tester avant la mise en ligne.
Introduction à Docker Compose comme solution d’Infrastructure As Code en CD
Les moyens de modulariser une recette Docker Compose
Le fichier compose.yaml ou docker-compose.yml décrit les services et leurs dépendances.
Comment faire une recette d'IAC adaptable à différents environnements ?
Les fichiers d’environnement pour les variables
Il est fréquent de créer un fichier .env contenant les variables (ex. ports, mots de passe, URLs).
Docker Compose peut en utiliser plusieurs.
L’avantage : vous séparez les paramètres généraux et spécifiques dans différents fichiers.
Les interpolations de variables (valeur par défaut)
À l’intérieur de votre docker-compose.yml, vous pouvez utiliser ${VARIABLE:-valeur_par_defaut}.
Cela permet de gagner en souplesse pour les environnements différents.
Le fichier [docker-]compose.override.yml
Compose cherche automatiquement un fichier compose.override.yaml, fusionné au principal.
Il sert à surcharger ou compléter la configuration (ex. volumes supplémentaires, commandes spécifiques). On peut ainsi éviter de multiplier les versions du fichier principal.
Les valeurs sont fusionnées en donnant la priorité à la surcharge dans la fusion.
# compose.yaml
webapp:
image: examples/web
ports:
- "8000:8000"
volumes:
- "/data"
# compose.override.yaml
webapp:
image: examples/web:dev
environment:
- DEBUG=1
# résultat
webapp:
image: examples/web:dev
ports:
- "8000:8000"
volumes:
- "/data"
environment:
- DEBUG=1
L'utilisation de plusieurs fichiers compose
La ligne de commande Compose accepte plusieurs fichiers en fusionnant les différentes versions.
docker compose -f compose.yaml -f compose.admin.yaml up -d
Comme pour le override, une fusion est opérée, qui favorise le dernier fichier dans la ligne de commande.
Les sections “extend” et “include”
Ces fonctions moins connues permettent de réutiliser des éléments de
Extend
Cette directive du service permet d'hériter la configurer d'un service dand un autre fichier (voire du même fichier).
# web.yml
services:
web:
extends:
file: common-services.yml
service: webapp
# common-services.yml
services:
webapp:
build: .
ports:
- "8000:8000"
volumes:
- "/data"
# resultat
services:
web:
build: .
ports:
- "8000:8000"
volumes:
- "/data"
Note: attention aux chemins des fichiers qui restent relatifs au chemin du fichier appelant.
Include
Cette directive de la racine permet d'intégrer des ressources mutualisées dans un fichier.
# default/my-compose-include.yaml
services:
serviceB:
image: myapp:0.0.1
# web.yml
include:
- ${INCLUDE_PATH:?default}/my-compose-include.yaml #with serviceB declared
services:
serviceA:
build: .
depends_on:
- serviceB #use serviceB directly as if it was declared in this Compose file
# Resultat
services:
serviceB:
image: myapp:0.0.1
serviceA:
build: .
depends_on:
- serviceB #use serviceB directly as if it was declared in this Compose file
On peut même utiliser des fusions locales et plusieurs path
include:
- path: ../commons/compose.yaml
project_directory: ..
env_file: ../another/.env
- path:
- ../lib/compose.yaml
- ./lib-override.yaml
Mise en place d’un workflow GitLab pour la CD
Le stage “deploy” dans .gitlab-ci.yml fait partie des stages par défaut.
Exemple :
# .gitlab-ci.yml
stages:
- build
- test
- deploy
# Utilise les environnements Gitlab
# cf. https://docs.gitlab.com/ci/environments/
deploy_production:
stage: deploy
only:
- main
script:
- echo "Starting deployment to production..."
- docker-compose pull
- docker-compose up -d
environment:
name: production
url: https://mon-app-prod.example.com
Ici, seules les merges vers la branche “main” peuvent déclencher le déploiement.
Les déploiements sont visibles dans l'interface de Gitlab et offrent une visibilité sur la CD.
Par exemple le fait d'avoir une URL est utilisé pour afficher un lien vers l'environnement.
Orchestration et bonnes pratiques de déploiement
Choix du mode de déclenchement : manuel, automatique, ou “pull-based”
Manuel (job manuel dans le pipeline)
- On ajoute un stage “deploy” dans GitLab CI qui ne s’exécute que quand un opérateur clique sur “Play”.
- Pratique pour la production : on valide les résultats des tests, on contrôle le moment exact du déploiement.
- Limite : si personne n’appuie sur le bouton, la prod peut rester en retard par rapport au code.
Automatique (déploiement continu dès que la CI est verte)
- Pipeline GitLab : on déclenche
deploy_jobsi tous les tests passent et si on est sur la branchemain. - Limite : en cas de lacune dans les tests, un bug peut partir directement en prod.
- Pipeline GitLab : on déclenche
Pull-based (GitOps-like)
- Le serveur (ou un service tiers) surveille le repository / registry et se met à jour.
- Limite : il faut concevoir un script ou un opérateur qui “poll” et qui gère les modifications (plus complexe avec Docker Compose).
Exemple de job manuel dans .gitlab-ci.yml :
stages:
- build
- test
- deploy
deploy_to_production:
stage: deploy
when: manual
only:
- main
script:
- echo "Déploiement manuel enclenché"
- ssh -o StrictHostKeyChecking=no $DEPLOY_USER@$DEPLOY_HOST "bash /home/stagiaire/deploy.sh"
Ici, le job n’est lancé qu’après un clic explicite, tout en restant lié à la branche principale.
Accès au code : clone/pull vs. push depuis le pipeline
Cloner le dépôt depuis le serveur
- Bonnes pratiques :
- Utiliser un Deploy Token ou une clé SSH dédiée, avec des droits read-only.
- Mettre ce token/clé dans un coffre ou dans des variables GitLab protégées.
- Critique :
- Certains déploient avec un utilisateur root ou une clé SSH trop permissive (risque de faille).
- On oublie parfois de révoquer un token quand il n’est plus nécessaire.
Exemple de script sur la VM (deploy.sh) :
#!/usr/bin/env bash
PROJECT_DIR="/home/stagiaire/myapp"
GIT_URL="https://$DEPLOY_TOKEN_USER:$DEPLOY_TOKEN_PASS@gitlab.com/mygroup/myapp.git"
if [ ! -d "$PROJECT_DIR" ]; then
git clone "$GIT_URL" "$PROJECT_DIR"
else
cd "$PROJECT_DIR"
git pull
fi
# Docker Compose update steps...
Ici, on se connecte au dépôt privé en fournissant le token. Mieux vaut stocker $DEPLOY_TOKEN_USER et $DEPLOY_TOKEN_PASS dans des variables d’environnement protégées (ou un .env local non versionné).
Pousser les fichiers depuis le pipeline
- Bonnes pratiques :
- On évite que la machine de déploiement ait accès direct au repo (pas besoin de token).
- Contrôle total dans le pipeline (scp du
docker-compose.ymlpar exemple).
- Critique :
- Peut devenir compliqué si on doit envoyer de nombreux fichiers ou sous-répertoires.
- Risque de divergence si le code local sur la VM n’est jamais synchronisé avec la branche.
Gestion des images et du “docker-compose pull”
Pour mettre à jour l’application, on veut récupérer l’image la plus récente. Typiquement :
docker login registry.gitlab.com -u "$CI_REGISTRY_USER" -p "$CI_REGISTRY_PASSWORD"
docker-compose pull
docker-compose up -d --remove-orphans
Bonnes pratiques
- Versionner les images avec des tags explicites (ex.
1.2.0,release-2025-03-05), plutôt quelatestqui peut être ambigu. - Faire un script de vérification post-déploiement (un “smoke test”) pour s’assurer que les conteneurs tournent correctement.
Risques
- Beaucoup d’équipes se contentent de “latest”, ce qui complique la traçabilité des versions et le rollback.
- Un “pull” systématique sans vérifier la compatibilité (database, config) peut casser la prod si on introduit une modification majeure.
Rolling update vs. arrêt/redémarrage
Rolling update :
- Docker Compose ne gère pas nativement le rolling update (contrairement à Swarm/Kubernetes).
- On peut écrire un script “maison” : créer un conteneur “v2”, vérifier sa santé, puis arrêter “v1”.
- Mais ce script devient vite complexe, surtout pour des apps avec plusieurs services interdépendants.
Arrêt/redémarrage (
downpuisup) :- Plus simple, mais il y a un downtime.
- Suffisant pour des petites équipes ou des services internes, moins pour un SaaS en 24/7.
Exemple rudimentaire :
docker-compose pull
docker-compose stop web
docker-compose rm -f web
docker-compose up -d web
Ici, on met à jour uniquement le service “web”. On peut imaginer un check entre “stop” et “up” pour vérifier l’état d’autres conteneurs.
Infrastructure as Code et modularité
Docker Compose se veut un début d’IaC (Infrastructure as Code). Cependant :
- Les bonnes pratiques :
- Avoir un
docker-compose.ymlcentral et des surcharges (docker-compose.override.yml,.env). - Gérer la configuration sensible via un gestionnaire de secrets ou des variables d’environnement (jamais en clair dans Git).
- Avoir un
- Les critiques :
- Beaucoup d’entreprises entassent dans un seul
docker-compose.ymltoutes les variables (ports, secrets, logs…) : c’est rapidement illisible. - Certains partent trop tard sur Swarm/Kubernetes alors qu’ils auraient besoin de fonctionnalités avancées (scaling, rolling updates automatiques).
- Beaucoup d’entreprises entassent dans un seul
Sécurité et critiques supplémentaires
Clés SSH non protégées :
- Mauvaise pratique : stocker la clé privée du serveur dans le dépôt Git.
- Bon réflexe : GitLab CI/CD variables (protégées), coffre-fort, ou solution de rotation automatique.
Lack of rollback :
- En Docker Compose “pur”, si on déploie une nouvelle image et qu’elle plante, on doit manuellement repasser à l’ancienne version.
- On peut conserver des tags plus anciens (ex.
:v1.2.2) pour relancer rapidement. - Certains scripts incluent un test post-déploiement et, en cas d’échec, réappliquent l’ancienne version.
Logs et supervision :
- Docker ne fournit pas de base de système de logs ou de monitoring centralisé.
- Bonnes pratiques : ajouter un ELK stack ou un service tiers (Datadog, Grafana Loki), configurer un healthcheck, etc.
- Critique : Beaucoup se contentent de “docker-compose logs -f” en prod, ce qui n’est pas suffisant pour une grosse application.
Évolution vers des orchestrateurs plus complets :
- Parfois, Docker Compose devient vite limitant (pas de scaling horizontal facile, pas de rolling updates).
- Kube, Swarm, Nomad sont des solutions qui gèrent plus finement les déploiements.
- Mais la migration vers ces outils peut être surdimensionnée pour une petite application ou une équipe réduite.
Exemple global d’un script de déploiement (critiqué et amélioré)
Ci-dessous, un script bash simplifié qui montre une pratique simple (pas de rollback, pas de checks) puis une amélioration.
#!/usr/bin/env bash
# -- Mauvaise Pratique --
cd /home/stagiaire/myapp
git pull
docker login registry.gitlab.com -u "deploy_token_user" -p "deploy_token_pass"
docker-compose pull
docker-compose up -d --remove-orphans
echo "Déploiement terminé"
Aucune vérification post-déploiement, aucune gestion d’erreur, tout est forcé à la suite.
Amélioration
#!/usr/bin/env bash
set -e # quitte sur la première erreur
PROJECT_DIR="/home/stagiaire/myapp"
BACKUP_TAG="rollback_$(date +%Y%m%d%H%M)"
cd "$PROJECT_DIR"
# Sauvegarder l'état git avant le pull
git rev-parse HEAD > last_commit.txt
# Pull du nouveau code
git pull || { echo "Échec du git pull"; exit 1; }
# Docker login si besoin
docker login registry.gitlab.com -u "$DEPLOY_TOKEN_USER" -p "$DEPLOY_TOKEN_PASS" || exit 1
# Tag l'ancienne version Docker Compose si besoin (pour rollback)
docker-compose images > "compose_images_${BACKUP_TAG}.txt"
# Mise à jour
docker-compose pull || { echo "Échec du docker-compose pull"; exit 1; }
docker-compose up -d --remove-orphans || {
echo "Échec du docker-compose up, rollback..."
# Rétablir la vieille version si possible
git checkout "$(cat last_commit.txt)"
docker-compose pull
docker-compose up -d --remove-orphans
exit 1
}
# Test de l'application (ex: curl d'un endpoint)
curl -f http://localhost:5000/health || {
echo "Application non fonctionnelle, rollback..."
git checkout "$(cat last_commit.txt)"
docker-compose pull
docker-compose up -d --remove-orphans
exit 1
}
echo "Déploiement réussi"
Points forts :
set -e: le script s’arrête sur la moindre erreur.- Rollback : si le
docker-compose up -déchoue ou si le check (curl) ne passe pas, on revient au commit précédent. - Sauvegarde : on conserve un petit log des images (
compose_images_*) et du commit. - Health check : on appelle
http://localhost:5000/health(endroit où l’app doit répondre “OK”), évitant un déploiement “à l’aveugle”.
Critique : c’est artisanal (mais souvent suffisant pour des petites applications). Pour plus de robustesse, un orchestrateur gère ces étapes (et le rollback) de façon intégrée.
Donc compose pour la CD...
- Ça convient à des applications de taille modeste ou des équipes n’ayant pas besoin d’un orchestrateur complet.
- Points de vigilance : versionning des images, sécurité des tokens/SSH, test post-déploiement, gestion des logs et du rollback.
- Un job GitLab manuel ou automatique, un script SSH, et un
docker-compose pull / upbasique sont la base. En améliorant ces scripts (checks, rollback, etc.), on limite les risques. - Si l’application grandit, on envisagera Docker Swarm, Kubernetes, ou une approche GitOps pour des déploiements plus fins et résilients.
En suivant ces bonnes pratiques (et en évitant les écueils évoqués), on assure un déploiement continu plus fiable, plus traçable et mieux adapté à la production.
Feedbacks et métriques de déploiement : propositions, exemples et critiques
Lorsque l’on met en place un déploiement continu (CD), il est essentiel de fournir un retour (feedback) aux équipes et d’analyser les métriques liées aux déploiements.
Voici un tour d’horizon des bonnes pratiques et des points de vigilance, avec des exemples de configuration pour les notifications (e-mail, Slack, Mattermost) et le suivi des métriques (temps de déploiement, fréquence).
Notifications automatiques : e-mail, Slack, Mattermost
Envoi d’e-mails via GitLab CI/CD
- Principe : GitLab peut envoyer des notifications e-mail (succès, échec, etc.) selon la configuration du compte ou du projet.
- Bonnes pratiques :
- Limiter les notifications aux événements critiques (échec, passage en production), pour éviter de saturer les boîtes mail.
- Personnaliser les sujets et contenus pour repérer rapidement le type d’environnement (staging, prod).
- Critique :
- Les e-mails sont peu interactifs ; difficile de discuter ou réagir rapidement.
- Risque de “notification fatigue” si trop de mails.
Le détail du paramétrage se fait sur l’interface GitLab, il n’y a pas de script direct.
Documentation : https://docs.gitlab.com/user/project/integrations/pipeline_status_emails/
Slack ou Mattermost (via webhook)
- Principe : On utilise un webhook pour poster un message (JSON) sur un canal Slack ou Mattermost.
- Bonnes pratiques :
- Envoyer un message en cas de réussite ou d’échec, en y ajoutant un lien vers le pipeline ou les logs.
- Personnaliser le message pour inclure le numéro de version, la branche, l’auteur du commit.
- Critique :
- Risque de spam si on déploie très souvent. Il faut configurer l’intégration pour n’envoyer que l’essentiel (uniquement sur la branche
main, par exemple). - Sur Slack/Mattermost, les messages défilent rapidement, donc la persistance et la traçabilité peuvent en souffrir.
- Risque de spam si on déploie très souvent. Il faut configurer l’intégration pour n’envoyer que l’essentiel (uniquement sur la branche
Exemple d’un job “notify_slack” :
notify_slack:
stage: notify
image: curlimages/curl:latest
script:
- |
curl -X POST \
-H "Content-type: application/json" \
--data '{"text":"Déploiement effectué sur la branche '$CI_COMMIT_BRANCH' : '$CI_COMMIT_TITLE' (pipeline '$CI_PIPELINE_ID')"}' \
"$SLACK_WEBHOOK_URL"
only:
- main
image: curlimages/curl:latest: on utilise une image légère disposant de la commandecurl.SLACK_WEBHOOK_URL: variable GitLab contenant l’URL du webhook Slack/Mattermost (protégée).only: - main: on notifie seulement pour la branche principale.
Approche critique des notifications
- Trop de notifications tuent la notification : envisagez des règles ou un agrégateur (ex. envoyez un résumé après plusieurs déploiements en “dev” plutôt qu’une notification pour chaque).
- Manque d’interactivité sur un simple webhook : pour avoir un retour “OK / FAIL” plus interactif, il existe des intégrations Slack/Mattermost plus avancées, mais ça demande de la configuration supplémentaire.
Métriques de déploiement
Au-delà du retour immédiat, il est essentiel de mesurer la performance du pipeline et la fréquence des mises à jour. Cela permet de détecter si l’on va vers un CD réellement fluide ou si des goulets d’étranglement subsistent.
Temps de déploiement (Deployment Time)
- Définition : la durée entre le lancement du job “deploy” et la fin effective du déploiement (ou la validation post-déploiement).
- Collecte :
- On peut enregistrer un timestamp au début et à la fin du job, et l’envoyer à un service de monitoring.
- GitLab propose dans “CI/CD > Pipelines” un récapitulatif des durées pour chaque job.
- Bonnes pratiques :
- Suivre l’évolution de ce temps dans le temps : un rallongement soudain peut révéler un problème (conteneurs trop lourds, latence réseau).
- Comparer la durée en staging et en production pour identifier d’éventuelles divergences.
Exemple :
deploy_job:
stage: deploy
script:
- START_TIME=$(date +%s)
- # ... actions de déploiement ...
- END_TIME=$(date +%s)
- DEPLOY_DURATION=$((END_TIME - START_TIME))
- echo "Deployment took $DEPLOY_DURATION seconds"
# Optionnel : on pourrait push ce chiffre vers un outil d'observabilité
Critique :
- Peu d’équipes exploitent réellement ce temps, alors qu’il donne une vision claire de la rapidité du pipeline.
- On oublie souvent de comptabiliser le temps de validation “manuelle” si le job est en “manual”.
Fréquence de déploiement (Deployment Frequency)
- Définition : combien de fois par jour/semaine/mois on déploie l’application.
- Utilité :
- Mesurer la capacité de livraison continue (CD) : si vous déployez tous les jours (ou plusieurs fois par jour), vous êtes proches du Continuous Deployment.
- Détecter des phases de blocage ou d’inactivité quand personne ne déploie.
- Collecte :
- Relever le nombre de “pipeline success” sur le stage “deploy” (par exemple via l’API GitLab).
- Ou garder un log dans une base (“à chaque déploiement, on incrémente un compteur.”).
Exemple :
notify_deployment_freq:
stage: notify
script:
- echo "Déploiement du jour #$(date +%j)" # ou n'importe quelle métrique
- # on peut imaginer envoyer un POST à un endpoint interne qui stocke la fréquence
only:
- main
Critique :
- La fréquence de déploiement ne fait pas tout : si vous déployez souvent mais que vos releases cassent régulièrement la prod, c’est contre-productif.
- Les équipes peuvent gonfler artificiellement la fréquence de déploiement sans apporter de valeur réelle.
Consolider et analyser les métriques (ex. DORA, logs)
Pour aller plus loin :
DORA Metrics (DevOps Research and Assessment)
- Lead Time : temps pour passer du commit au déploiement.
- Deployment Frequency : nombre de déploiements.
- Change Failure Rate : pourcentage de déploiements qui échouent ou induisent un rollback.
- Time to Restore : durée pour restaurer un service en cas d’incident.
Intégration avec des outils de monitoring
- Prometheus / Grafana : si on veut des dashboards plus détaillés, on peut pousser (via un exporter) les données de pipeline GitLab (nombre de runs, temps moyen, etc.).
- ELK (Elasticsearch, Logstash, Kibana) : regrouper les logs de déploiement, visualiser tendances, anomalies.
Critique :
- Accumuler des métriques ne sert à rien si on ne débouche pas sur des actions (optimisations, correctifs).
- Risque de “vanity metrics” : on se félicite d’un certain nombre de déploiements ou d’un temps de déploiement court, mais on oublie la qualité du code, la satisfaction client, etc.
Exemples concrets de configuration GitLab CI pour feedback et métriques
Pipeline complet avec notifications Slack et enregistrement de la durée
stages:
- build
- test
- deploy
- notify
build_job:
stage: build
script:
- echo "Building..."
# ... build image, push, etc.
test_job:
stage: test
script:
- echo "Testing..."
# ... run tests
deploy_job:
stage: deploy
script:
- START_TIME=$(date +%s)
- # script de déploiement : ssh, docker-compose pull, etc.
- END_TIME=$(date +%s)
- DEPLOY_DURATION=$((END_TIME - START_TIME))
- echo "DEPLOY_DURATION=$DEPLOY_DURATION" >> deploy_vars.txt
artifacts:
name: "deploy-artifacts"
paths:
- deploy_vars.txt
notify_slack:
stage: notify
image: curlimages/curl:latest
dependencies:
- deploy_job
script:
- source deploy_vars.txt
- |
curl -X POST \
-H "Content-type: application/json" \
--data '{"text":"Déploiement effectué en '$DEPLOY_DURATION' secondes. Détails pipeline '$CI_PIPELINE_ID'."}' \
"$SLACK_WEBHOOK_URL"
only:
- main
Points de vigilance
- Surabondance de notifications : trop de mails ou de messages Slack/Mattermost peut créer de la fatigue et noyer l’information critique.
- Qualité vs. quantité : la fréquence de déploiement élevée ne vaut rien si les releases sont instables.
- Exploitation des métriques : il faut qu’elles servent de base à des rétrospectives, des améliorations continues (ex. pourquoi la durée de déploiement a doublé ? pourquoi tel déploiement a échoué ?).
- Sécurité : protéger les webhooks Slack (variables GitLab), limiter leur diffusion.
- Évolutions : si on veut un système plus poussé (par ex. regroupement automatique, gestion d’escalades en cas d’échec), il existe des intégrations GitLab vers Opsgenie, PagerDuty, ou des frameworks plus avancés.